 srcmini
srcmini本文概述
消费者是通过主题消费或从Kafka集群读取数据的消费者。消费者还知道应该从哪个代理读取数据。使用者以有序的方式读取每个分区中的数据。这意味着使用者不应该在从偏移量0读取之前先从偏移量1读取数据。而且,使用者可以轻松地同时从多个代理读取数据。
例如,两个消费者,即消费者1和消费者2正在读取数据。使用者1正在按顺序从代理1读取数据。另一方面,消费者2正在同时从Broker 2和Broker 3依次读取数据。
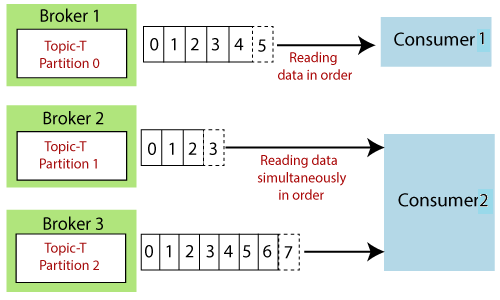
注意:使用者2正在并行地从代理2和代理3读取数据。因此,代理2下的偏移2与代理3下的偏移2中包含的数据没有任何关系。
消费群体
消费者组是一组基本针对应用程序的多个消费者。组中存在的每个使用者都直接从互斥分区读取数据。如果使用者的数量大于分区的数量,则某些使用者将处于非活动状态。不知何故,如果我们失去了组内任何活动的使用者,则不活动的使用者可以接管并进入活动状态以读取数据。
但是,如何确定哪个使用者应该首先读取数据以及从哪个分区读取数据呢?
对于此类决策,组内的使用者会自动使用一个“ GroupCoordinator”和一个“ ConsumerCoordinator”,后者将一个使用者分配到一个分区。该功能已在Kafka中实现。因此,用户无需担心。
让我们看下面的例子。
例子1
考虑两组消费者,即消费者组1和消费者组2。组1的两个使用者都一起从不同的分区读取数据。组1的两个使用者都将保持活动状态,因为他们正在并行读取数据。
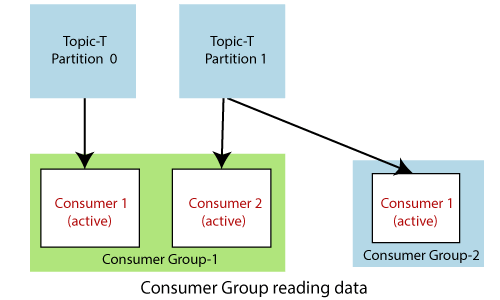
另一方面,组2的使用者1也正在主题T下从分区1读取数据。此处,消费者也处于活动状态,因为它属于组2。
例子2
考虑另一个场景,其中一个消费者组有三个消费者。消费者1和消费者2处于活动状态。使用者1正在从分区0读取数据,而使用者2正在从分区1读取数据。同样,只有两个可用的主题分区,但是有三个使用者。因此,消费者3将保持不活动状态,直到任何活动的消费者离开。
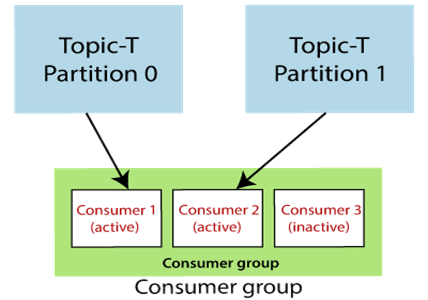
注意:在示例2中,三个消费方仅出现在一组中。这就是为什么消费者3不活动的原因。但是,如果使用者在另一个组中,则它将处于活动状态并能够读取数据。
消费者抵销
Apache Kafka提供了一种方便的功能来存储使用者组的偏移值。它存储偏移量值,以了解使用者组正在哪个分区读取数据。组中的使用者一旦读取数据,Kafka就会自动提交偏移量,或者可以对其进行编程。这些偏移是在称为__consumer_offsets的主题中实时提交的。此功能是在使用方无法读取数据的机器故障的情况下实现的。因此,由于抵消的承诺,消费者将能够继续从中断处读取数据。
例如,
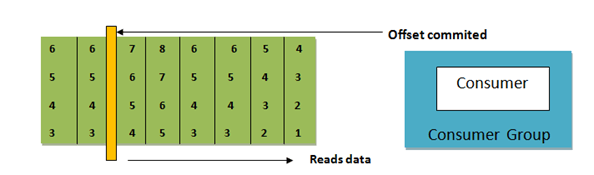
在下图中,来自消费者组的消费者正在读取数据。读取数据后,使用者已提交偏移量。这意味着下次,消费者将不会从头开始读取数据,而是从提交的点开始读取数据。同样,消费者以某种方式死亡,它将只能从承诺状态继续。
传递语义
承诺的选择取决于消费者,即消费者何时希望承担补偿。提交偏移量就像读者在阅读书籍或小说时使用的书签。
在Kafka中,使用了以下三种传递语义:
- 最多一次:这里,偏移量在使用者接收到消息后立即提交。但是,如果处理不正确,消息将丢失,并且使用者将无法进一步读取。因此,这种语义是最不优选的。
- 至少一次:在此,偏移量在处理完消息后提交。如果处理出错,则消费者将再次读取该消息。因此,通常首选使用它。由于消费者可以阅读两次消息,因此将导致重复处理消息。因此,它需要一个系统成为幂等系统。
- 恰好一次:这里,仅使用Kafka Streams API即可实现从Kafka到Kafka工作流程的偏移量。为了实现Kafka与外部系统的抵销,我们需要使用幂等的消费者。
评论前必须登录!
注册