 srcmini
srcmini本文概要
机器学习赋予计算机系统自动学习的能力,而不需要显式编程。但是机器学习系统是如何工作的呢?因此,它可以用机器学习的生命周期来描述。机器学习生命周期是一个建立高效机器学习项目的循环过程。生命周期的主要目的是找到问题或项目的解决方案。
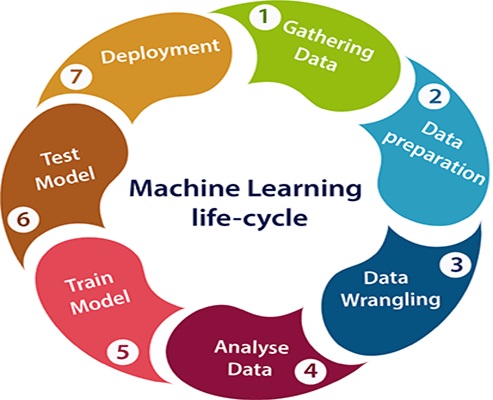
机器学习的生命周期包括七个主要步骤,如下所示:
- 收集数据
- 数据准备
- 数据整理
- 分析数据
- 训练模型
- 测试模型
- 部署
在整个过程中最重要的是理解问题,知道问题的目的。因此,在开始生命周期之前,我们需要了解问题,因为好的结果取决于对问题的更好理解。
在完整的生命周期过程中,为了解决一个问题,我们创建了一个称为“模型”的机器学习系统,这个模型是通过提供“训练”来创建的。但是为了训练一个模型,我们需要数据,因此,生命周期从收集数据开始。
1.收集数据
数据收集是机器学习生命周期的第一步。这一步的目标是识别并获得所有与数据相关的问题。
在这一步中,我们需要识别不同的数据源,因为可以从各种数据源收集数据,比如文件、数据库、internet或移动设备。它是生命周期中最重要的步骤之一。收集数据的数量和质量将决定输出的效率。数据越多,预测就越准确。
此步骤包括以下任务:
- 识别各种数据源
- 收集数据
- 整合来自不同源获得的数据
通过执行上述任务,我们有一个连贯的一组数据,也被称为数据集。这将在进一步的步骤中使用。
2.数据准备
收集数据后,我们需要为下一步做准备。数据准备是我们将数据放入合适的位置并准备用于机器学习训练的一个步骤。
在这一步,首先,我们把所有的数据放在一起,然后随机排序的数据。
该步骤可以被进一步分为两个过程:
- 数据探索:它被用来理解我们必须处理的数据的性质。我们需要了解数据的特征、格式和质量。更好地理解数据会带来有效的结果。在这里,我们发现了相关性、总体趋势和异常值。
- 数据预处理:现在,下一步是对数据进行预处理以进行分析。
3.数据整理
数据整理是将原始数据清理并转换为可用格式的过程。它是一个清除数据、选择要使用的变量、将数据转换成适当格式以使其更适合下一步分析的过程。这是整个过程中最重要的步骤之一。为了解决质量问题,需要对数据进行清理。
我们收集的数据不一定总是有用的,因为有些数据可能没用。在实际应用程序中,收集的数据可能存在各种问题,包括
- 缺失值
- 重复数据
- 无效数据
- 噪声
所以,我们使用各种过滤技术来清理数据。
必须检测并消除上述问题,因为它会对结果的质量产生负面影响。
4.数据分析
现在,清理和准备的数据被传递到分析步骤。这一步涉及到
- 分析技术的选择
- 构建模型
- 查看结果
这一步的目的是建立一个机器学习模型,使用各种分析技术分析数据,并审查结果。首先确定问题的类型,选择分类、回归、聚类分析、关联等机器学习技术,利用准备好的数据建立模型,并对模型进行评估。
因此,在这一步,我们采取的数据和使用机器学习算法来建立模型。
5.训练模型
现在,下一步是训练模型,在这一步中,我们训练我们的模型来提高它的性能,以获得更好的问题结果。
我们使用数据集来训练模型使用各种机器学习算法。需要对模型进行训练,使其能够理解各种模式、规则和特性。
6.测试模型
一旦我们的机器学习模型被训练到给定的数据集上,我们就可以测试这个模型。在这一步中,我们通过向模型提供测试数据集来检查模型的准确性。
对模型的测试根据项目或问题的需求确定模型的百分精度。
7.部署
机器学习生命周期的最后一步是部署,我们将模型部署到实际系统中。
如果上述模型能够按照我们的要求以可接受的速度生成准确的结果,那么我们就可以将该模型部署到实际系统中。但是在部署项目之前,我们将检查它是否在利用现有数据改进其性能。部署阶段类似于为项目生成最终报告。
评论前必须登录!
注册