 srcmini
srcmini多年来, Python在数据科学中的使用已以惊人的速度增长, 并且每天都在不断增长。
数据科学是一个广阔的研究领域, 包含许多子领域, 毫无疑问, 数据分析是所有这些领域中最重要的领域之一, 无论数据科学的技术水平如何, 理解或掌握它都变得越来越重要。至少具有基本知识。
什么是数据分析?
数据分析是对大量非结构化或非组织化数据的清理和转换, 目的是生成有关此数据的关键见解和信息, 这将有助于做出明智的决策。
有许多用于数据分析的工具, Python, Microsoft Excel, Tableau, SaS等, 但是在本文中, 我们将重点介绍如何在python中完成数据分析。更具体地说, 它是如何通过名为Pandas的python库完成的。
什么是熊猫?
Pandas是一个开放源代码的Python库, 用于数据操作和处理。它快速高效, 并且具有将多种数据加载到内存中的工具。它可以用于重塑, 标注切片, 索引甚至对几种形式的数据进行分组。
熊猫中的数据结构
熊猫有3种数据结构, 分别是:
- 系列
- 数据框
- 面板
区分其中三个的最佳方法是将一个视为包含多个其他堆栈。因此, DataFrame是一系列堆栈, Panel是DataFrame堆栈。
系列是一维数组
几个系列的堆栈构成一个二维DataFrame
几个DataFrame的堆栈构成一个3维面板
我们最常使用的数据结构是二维DataFrame, 它也可能是我们可能遇到的某些数据集的默认表示方式。
熊猫中的数据分析
对于本文, 无需安装。我们将使用Google创建的名为colaboratory的工具。这是用于数据分析, 机器学习和AI的在线python环境。它只是一个基于云的Jupyter Notebook, 预装了你作为数据科学家所需的几乎所有python软件包。
现在, 转到https://colab.research.google.com/notebooks/intro.ipynb。你应该看到以下内容。
通过左上角的导航, 单击文件选项, 然后单击”新笔记本”选项。你会在浏览器中看到一个新的Jupyter笔记本页面。我们要做的第一件事是将熊猫导入我们的工作环境。我们可以通过运行以下代码来做到这一点;
import pandas as pd对于本文, 我们将使用房价数据集进行数据分析。我们将使用的数据集可以在这里找到。我们要做的第一件事是将数据集加载到我们的环境中。
我们可以在新的单元格中使用以下代码来完成此操作;
df = pd.read_csv('https://firebasestorage.googleapis.com/v0/b/ai6-portfolio-abeokuta.appspot.com/o/kc_house_data.csv?alt=media &token=6a5ab32c-3cac-42b3-b534-4dbd0e4bdbc0 ', sep=', ')当我们想读取CSV文件时, 使用了.read_csv, 并传递了sep属性来显示CSV文件以逗号分隔。
我们还应该注意, 加载的CSV文件存储在变量df中。
我们不需要在Jupyter Notebook中使用print()函数。我们只需在单元格中键入一个变量名, Jupyter Notebook就会为我们打印出来。
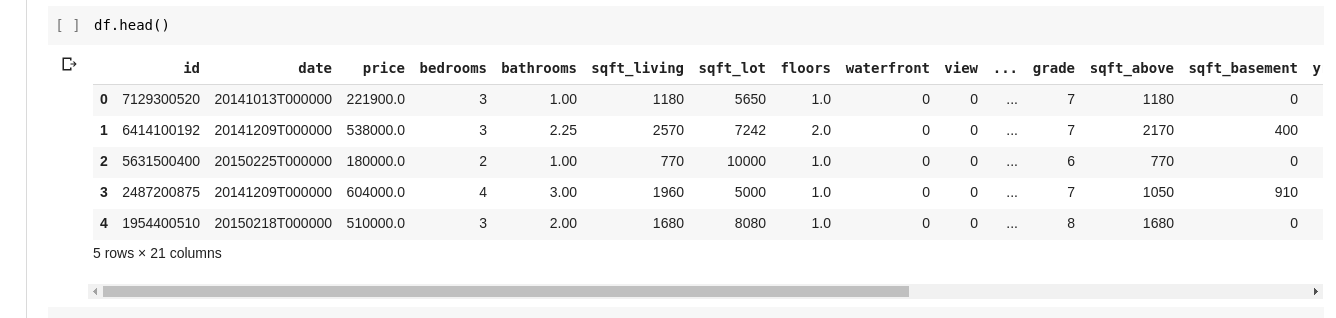
我们可以通过在新单元格中键入df并运行它来进行尝试, 它将为我们打印出数据集中的所有数据作为DataFrame。
但是我们并不总是希望看到所有数据, 有时我们只是想看到前几个数据及其列名。我们可以使用df.head()函数打印前五列, 并使用df.tail()打印后五列。两者之一的输出看起来都是这样。
我们想要检查数据的几行和几列之间的关系。 .describe()函数正是为我们做到了这一点。
运行df.describe()会得到以下输出;
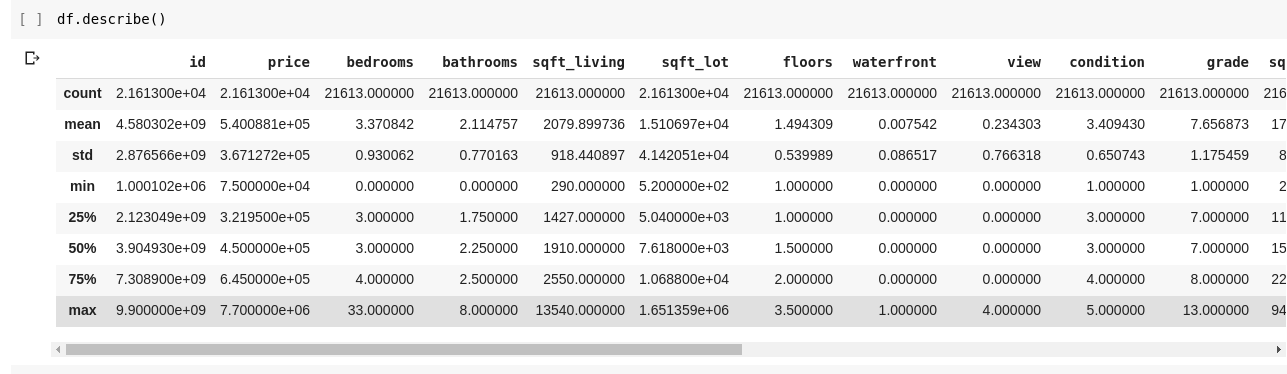
我们可以立即看到.describe()给出了DataFrame中每一列的平均值, 标准差, 最小值和最大值以及百分位数。这特别有用。
我们还可以检查2D DataFrame的形状, 以了解其具有多少行和列。我们可以使用df.shape做到这一点, 它以格式(行, 列)返回一个元组。
我们还可以使用df.columns检查DataFrame中所有列的名称。
如果我们只选择一列并返回其中的所有数据怎么办?这样做的方法类似于对字典进行切片。在新的单元格中键入以下代码并运行它
df['price ']上面的代码返回了price列, 我们可以通过将其保存到新变量中来进一步
price = df['price']现在, 我们可以对我们的价格变量的DataFrame执行其他所有操作, 因为它只是实际DataFrame的子集。我们可以做df.head(), df.shape等之类的东西。
我们也可以通过将列名称列表传递给df来选择多个列
data = df[['price ', 'bedrooms']]上面选择了名称为” price”和” bedrooms”的列, 如果我们在新的单元格中输入data.head(), 则会得到以下内容
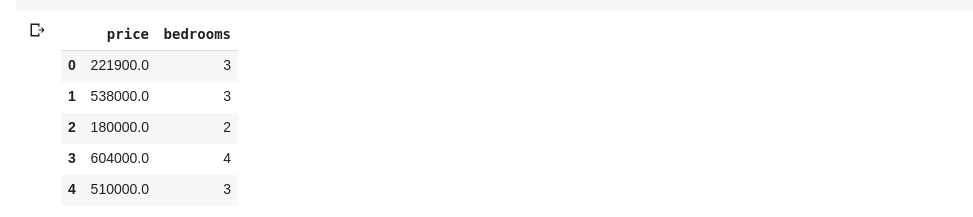
上面对列进行切片的方式返回了该列中的所有行元素, 如果我们想从数据集中返回行的子集和列的子集怎么办?这可以使用.iloc来完成, 并以类似于python列表的方式进行索引。所以我们可以做类似的事情
df.iloc[50: , 3]从第50行到最后返回第三列。它非常整洁, 与python中的切片列表相同。
现在, 让我们做一些非常有趣的事情, 我们的房价数据集中有一个列告诉我们房子的价格, 而另一列告诉我们该房子所拥有的卧室数量。房屋价格是一个连续的价格, 因此我们可能没有两个价格相同的房屋。但是卧室的数量是离散的, 因此我们可以有几间带有两, 三, 四间卧室的房屋, 等等。
如果我们想获得所有具有相同卧室数量的房屋并找到每个独立卧室的均价怎么办?在大熊猫中这样做比较容易, 可以这样做。
df.groupby('bedrooms ')['price '].mean()上面首先使用df.groupby()函数将具有相同卧室编号的数据集对DataFrame进行分组, 然后告诉它只给我们提供卧室列, 然后使用.mean()函数在数据集中查找每个房屋的均值。
如果我们想可视化以上内容怎么办?我们希望能够检查每个不同卧室数量的平均价格如何变化?我们只需要将前面的代码链接到.plot()函数, 就可以了。
df.groupby('bedrooms ')['price '].mean().plot()我们将得到一个看起来像这样的输出;
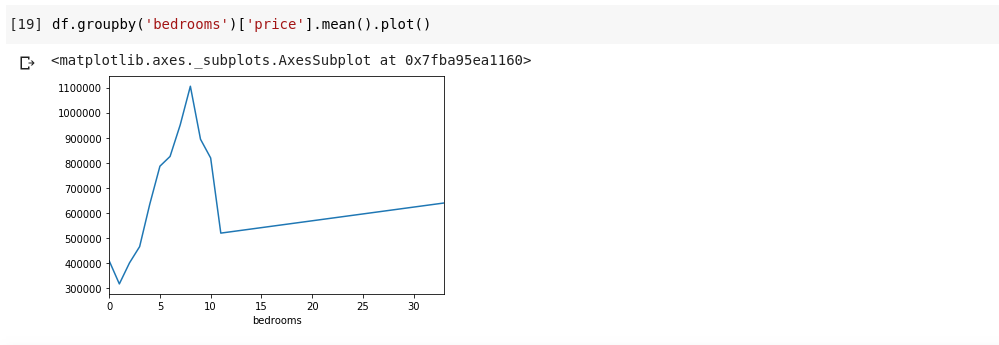
上面显示了数据的一些趋势。在水平轴上, 我们有不同数量的卧室(请注意, 多于一个房屋可以有X个卧室), 在垂直轴上, 我们具有相对于水平卧房数量的价格平均值轴。现在我们可以立即注意到, 拥有5到10间卧室的房屋比拥有3间卧室的房屋要贵得多。同样显而易见的是, 拥有7或8个卧室的房屋比拥有15、20甚至30个房间的房屋要贵得多。
上面的信息说明了数据分析非常重要的原因, 我们能够从数据中提取有用的见解, 而这些数据如果不进行分析就不会立即或几乎无法注意到。
缺失数据
假设我要进行的调查中包含一系列问题。我与成千上万的人共享了该调查的链接, 以便他们提供反馈。我的最终目标是对该数据进行数据分析, 以便从数据中获得一些关键见解。
现在很多事情可能出问题了, 一些测量师可能会不舒服地回答我的一些问题, 然后将其留空。很多人可以对我的调查问题的某些部分做同样的事情。这可能不算问题, 但可以想象一下, 如果我要在调查中收集数值数据, 而部分分析需要我获取总和, 均值或其他某种算术运算。在我的分析中, 一些缺失值会导致很多不准确, 我必须找出一种方法来查找和替换这些缺失值, 并用一些可以替代它们的值替代。
熊猫为我们提供了一个函数, 该函数可在称为isull()的数据帧中查找缺失值。
可以这样使用notull()函数;
df.isnull()这将返回一个布尔值的DataFrame, 它告诉我们最初存在的数据是True还是False。输出看起来像这样;
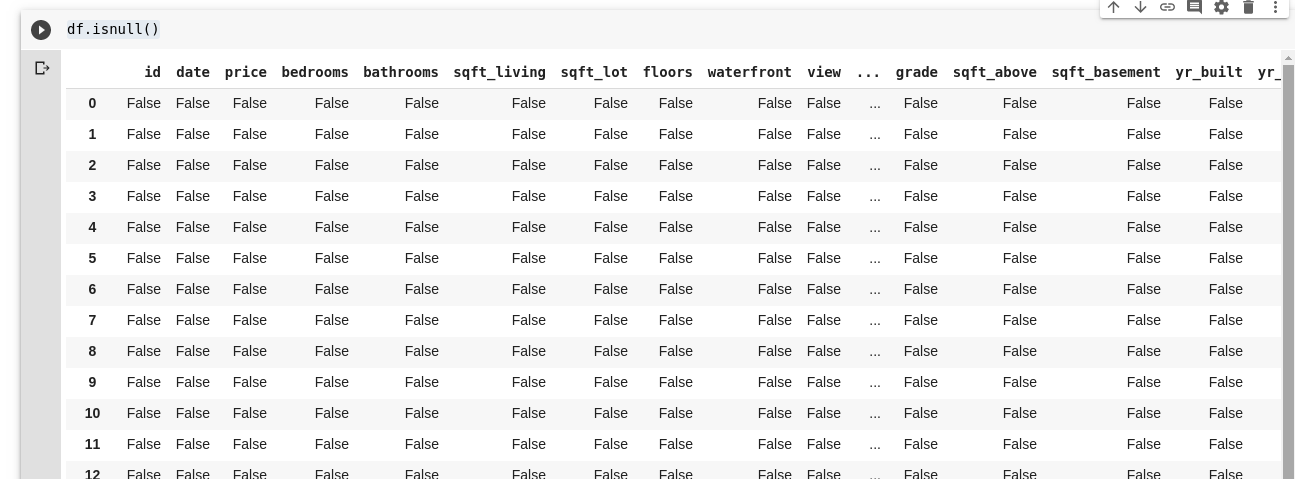
我们需要一种能够替换所有这些缺失值的方法, 大多数情况下, 缺失值的选择可以视为零。有时, 可以将其视为所有其他数据的均值或周围数据的均值, 具体取决于数据科学家和所分析数据的用例。
为了填充DataFrame中所有缺少的值, 我们使用.fillna()函数, 其用法如下:
df.fillna(0)在上面, 我们用零值填充所有空白数据。也可以是我们指定的其他任何数字。
数据的重要性不可过分强调, 它有助于我们从数据本身中正确地获得答案!他们说, 数据分析是数字经济的新动力。
可以在这里找到本文中的所有示例。
要更深入地学习, 请查看”使用Python和Pandas进行数据分析”在线课程。
评论前必须登录!
注册