 srcmini
srcmini本文概述

检测所谓的”假新闻”绝非易事。首先, 要定义什么是假新闻-鉴于假新闻现在已成为政治声明。如果可以找到定义或就其达成共识, 则必须收集并正确标记真实和虚假新闻(希望在相似的主题上能最好地显示清楚的区别)。收集到信息后, 你必须找到有用的功能, 才能根据真实新闻确定伪造品。
为了更深入地了解这个问题空间, 我建议看一下Miguel Martinez-Alvarez的文章”机器学习和AI如何帮助解决假新闻问题”。
大约在阅读Miguel有洞察力的文章的同时, 我遇到了一个开放数据科学文章, 内容涉及使用贝叶斯模型构建成功的假新闻检测器。作者甚至使用标记的假新闻和真实新闻示例的数据集创建了一个存储库。我很好奇能否轻松重现结果, 然后确定模型学到了什么。
在本教程中, 你将一起完成我的一些初步探索, 看看是否可以构建成功的假新闻检测器!
提示:如果你想了解有关自然语言处理(NLP)基础的更多信息, 请考虑学习Python中的自然语言处理基础知识。
数据探索
首先, 你应该始终快速浏览一下数据并对其内容有所了解。为此, 请使用Pandas DataFrame并检查形状, 头部并应用任何必要的转换。
提取训练数据
现在, DataFrame看起来更接近你的需求, 你想要分离标签并设置训练和测试数据集。
对于此笔记本, 我决定专注于使用较长的文章文字。因为我知道我将使用单词袋和术语频率-逆文档频率(TF-IDF)来提取特征, 所以这似乎是一个不错的选择。希望使用更长的文字可以为我的真实和虚假新闻数据提供不同的单词和功能。
构建矢量化器分类器
有了训练和测试数据后, 就可以构建分类器了。为了弄清楚文章中的单词和标记是否对新闻是假新闻还是真实新闻有重大影响, 你首先使用CountVectorizer和TfidfVectorizer。
你将看到该示例使用max_df参数将TF-IDF矢量化器tfidf_vectorizer的最大阈值设置为.7。这会删除出现在文章中70%以上的单词。同样, 内置的stop_words参数将在制作向量之前从数据中删除英语停用词。
还有更多可用的参数, 你可以在scikit-learn文档中了解有关TfidfVectorizer和CountVectorizer的所有信息。
既然有了向量, 就可以查看存储在count_vectorizer和tfidf_vectorizer中的向量特征。
有什么明显的问题吗? (是!)
在你一直在使用的数据集中, 显然有注释, 度量或其他无意义的词以及多语种文章。通常, 你可能希望花更多的时间进行预处理并消除噪声, 但是由于本教程仅展示了一个小的概念证明, 因此你将了解模型是否可以克服噪声并在存在这些问题的情况下进行正确分类。
Intermezzo:计数与TF-IDF功能
我很好奇我的计数和TF-IDF矢量化器是否提取了不同的令牌。要查看并比较功能, 可以将向量信息提取回DataFrame中, 以使用简单的Python比较。
如你所见, 通过运行下面的单元格, 两个矢量化器都提取了相同的令牌, 但显然具有不同的权重。可能的是, 更改TF-IDF矢量化器的max_df和min_df可能会改变结果, 并导致每个特征不同。
在[15]中:
count_df = pd.DataFrame(count_train.A, columns=count_vectorizer.get_feature_names())
在[16]中:
tfidf_df = pd.DataFrame(tfidf_train.A, columns=tfidf_vectorizer.get_feature_names())
在[17]中:
difference = set(count_df.columns) - set(tfidf_df.columns)
difference
出[17]:
set()在[18]中:
print(count_df.equals(tfidf_df))
False
在[19]中:
count_df.head()
出[19]:
| 00 | 000 | 0000 | 00000031 | 000035 | 00006 | 0001 | 0001pt | 000英尺 | 000公里 | … | 阿勒颇 | 阿拉伯文 | 关于 | 还没 | 什么 | 尝试次数 | 来自 | 这个 | 又恶心 | 永阿德 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 2 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 3 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| 4 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | … | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
5行×56922列
在[20]中:
tfidf_df.head()
出[20]:
| 00 | 000 | 0000 | 00000031 | 000035 | 00006 | 0001 | 0001pt | 000英尺 | 000公里 | … | 阿勒颇 | 阿拉伯文 | 关于 | 还没 | 什么 | 尝试次数 | 来自 | 这个 | 又恶心 | 永阿德 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | … | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 1 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | … | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 2 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | … | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 3 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | … | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
| 4 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | … | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 |
5行×56922列
比较模型
现在是时候训练和测试你的模型了。
在这里, 你将从NLP最喜欢的MultinomialNB开始。你可以使用它来比较TF-IDF和词袋。我的直觉是词袋(也称为CountVectorizer)在此模型下会更好。 (要获得更多关于多项式分布以及为什么它最适合整数的阅读, 请从UPenn统计课程中查看这个相当简洁的解释)。
我个人发现混淆矩阵更易于比较和阅读, 因此我使用了scikit-learn文档来构建一些易于理解的混淆矩阵(感谢开源!)。混淆矩阵会在主对角线上(左上至右下)显示正确的标签。其他单元格显示不正确的标签, 通常称为误报或误报。根据你的问题, 其中之一可能更重要。例如, 对于虚假新闻问题, 我们不将真实新闻文章标记为虚假新闻是否更重要?如果是这样, 我们可能最终希望对我们的准确性得分进行加权, 以更好地反映这一担忧。
除了混淆矩阵之外, scikit-learn还提供了许多可视化和比较模型的方法。一种流行的方法是使用ROC曲线。 scikit学习指标模块中提供了许多其他评估模型的方法。
在[21]中:
def plot_confusion_matrix(cm, classes, normalize=False, title='Confusion matrix', cmap=plt.cm.Blues):
"""
See full source and example:
http://scikit-learn.org/stable/auto_examples/model_selection/plot_confusion_matrix.html
This function prints and plots the confusion matrix.
Normalization can be applied by setting `normalize=True`.
"""
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45)
plt.yticks(tick_marks, classes)
if normalize:
cm = cm.astype('float') / cm.sum(axis=1)[:, np.newaxis]
print("Normalized confusion matrix")
else:
print('Confusion matrix, without normalization')
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, cm[i, j], horizontalalignment="center", color="white" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
在[22]中:
clf = MultinomialNB()
在[23]中:
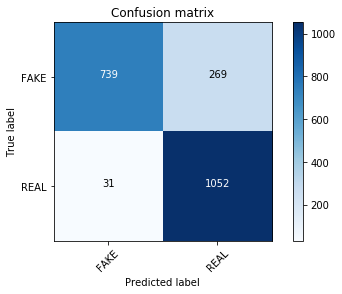
clf.fit(tfidf_train, y_train)
pred = clf.predict(tfidf_test)
score = metrics.accuracy_score(y_test, pred)
print("accuracy: %0.3f" % score)
cm = metrics.confusion_matrix(y_test, pred, labels=['FAKE', 'REAL'])
plot_confusion_matrix(cm, classes=['FAKE', 'REAL'])
accuracy: 0.857
Confusion matrix, without normalization
在[24]中:
clf = MultinomialNB()
在[25]中:
clf.fit(count_train, y_train)
pred = clf.predict(count_test)
score = metrics.accuracy_score(y_test, pred)
print("accuracy: %0.3f" % score)
cm = metrics.confusion_matrix(y_test, pred, labels=['FAKE', 'REAL'])
plot_confusion_matrix(cm, classes=['FAKE', 'REAL'])
accuracy: 0.893
Confusion matrix, without normalization
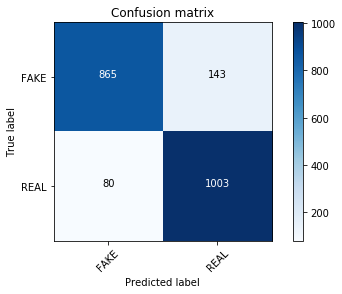
确实, 在绝对没有参数调整的情况下, 你的计数向量化训练集count_train明显优于TF-IDF向量!
测试线性模型
关于线性模型如何与TF-IDF矢量化器很好地结合使用, 有很多很棒的文章(请看word2vec进行分类, 在scikit-learn文本分析中参考SVM, 等等)。
所以你应该使用SVM, 对吗?
好吧, 我最近观看了Victor Lavrenko关于文本分类的演讲, 他将Passive Aggressive分类器与用于文本分类的线性SVM进行了比较。我们将使用伪造的新闻数据集测试这种方法(这种方法具有明显的速度优势和永久性的学习劣势)。
在[26]中:
linear_clf = PassiveAggressiveClassifier(n_iter=50)
在[27]中:
linear_clf.fit(tfidf_train, y_train)
pred = linear_clf.predict(tfidf_test)
score = metrics.accuracy_score(y_test, pred)
print("accuracy: %0.3f" % score)
cm = metrics.confusion_matrix(y_test, pred, labels=['FAKE', 'REAL'])
plot_confusion_matrix(cm, classes=['FAKE', 'REAL'])
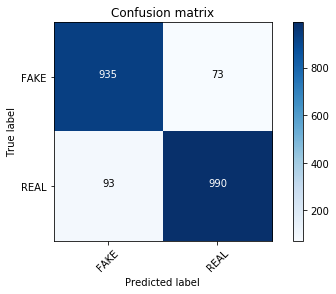
accuracy: 0.936
Confusion matrix, without normalization
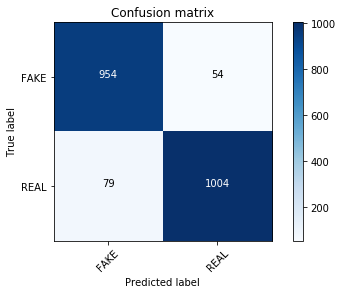
哇!
我印象深刻混淆矩阵看起来有所不同, 该模型对我们的假新闻进行了更好的分类。我们可以测试调整MultinomialNB的alpha值是否会产生可比较的结果。你还可以将参数调整与网格搜索一起使用, 以进行更详尽的搜索。
在[28]中:
clf = MultinomialNB(alpha=0.1)
在[29]中:
last_score = 0
for alpha in np.arange(0, 1, .1):
nb_classifier = MultinomialNB(alpha=alpha)
nb_classifier.fit(tfidf_train, y_train)
pred = nb_classifier.predict(tfidf_test)
score = metrics.accuracy_score(y_test, pred)
if score > last_score:
clf = nb_classifier
print("Alpha: {:.2f} Score: {:.5f}".format(alpha, score))
Alpha: 0.00 Score: 0.61502
Alpha: 0.10 Score: 0.89766
Alpha: 0.20 Score: 0.89383
Alpha: 0.30 Score: 0.89000
Alpha: 0.40 Score: 0.88570
Alpha: 0.50 Score: 0.88427
Alpha: 0.60 Score: 0.87470
Alpha: 0.70 Score: 0.87040
Alpha: 0.80 Score: 0.86609
Alpha: 0.90 Score: 0.85892
不完全是……在这一点上, 可能需要对所有分类器进行参数调整, 或者看看其他scikit-learn贝叶斯分类器。你还可以使用支持向量机(SVM)进行测试, 以查看其性能是否超过了Passive Aggressive分类器。
但是我对被动进取模型实际上学到了些什么感到好奇。因此, 让我们开始内省。
内省模型
假新闻解决了, 对吧?我们的数据集准确率达到了93%, 因此让我们全都关闭商店然后回家。
当然不是。鉴于我们在功能中看到了多少噪音, 我对这些结果充其量也保持警惕。在StackOverflow上有一篇很好的文章, 它具有极其有用的功能, 可用于查找对标签影响最大的向量。它仅适用于二进制分类(具有2个类的分类器), 但这对你来说是个好消息, 因为你只有FAKE或REAL标签。
将性能最好的分类器与TF-IDF向量数据集(tfidf_vectorizer)和被动积极分类器(linear_clf)结合使用, 检查前30个向量是否存在假新闻和真实新闻:
在[30]中:
def most_informative_feature_for_binary_classification(vectorizer, classifier, n=100):
"""
See: https://stackoverflow.com/a/26980472
Identify most important features if given a vectorizer and binary classifier. Set n to the number
of weighted features you would like to show. (Note: current implementation merely prints and does not
return top classes.)
"""
class_labels = classifier.classes_
feature_names = vectorizer.get_feature_names()
topn_class1 = sorted(zip(classifier.coef_[0], feature_names))[:n]
topn_class2 = sorted(zip(classifier.coef_[0], feature_names))[-n:]
for coef, feat in topn_class1:
print(class_labels[0], coef, feat)
print()
for coef, feat in reversed(topn_class2):
print(class_labels[1], coef, feat)
most_informative_feature_for_binary_classification(tfidf_vectorizer, linear_clf, n=30)
FAKE -4.86382369883 2016
FAKE -4.13847157932 hillary
FAKE -3.98994974843 october
FAKE -3.10552662226 share
FAKE -2.99713810694 november
FAKE -2.9150746075 article
FAKE -2.54532100449 print
FAKE -2.47115243995 advertisement
FAKE -2.35915304509 source
FAKE -2.31585837413 email
FAKE -2.27985826579 election
FAKE -2.2736680857 oct
FAKE -2.25253568246 war
FAKE -2.19663276969 mosul
FAKE -2.17921304122 podesta
FAKE -1.99361009573 nov
FAKE -1.98662624907 com
FAKE -1.9452527887 establishment
FAKE -1.86869495684 corporate
FAKE -1.84166664376 wikileaks
FAKE -1.7936566878 26
FAKE -1.75686475396 donald
FAKE -1.74951154055 snip
FAKE -1.73298170472 mainstream
FAKE -1.71365596627 uk
FAKE -1.70917804969 ayotte
FAKE -1.70781651904 entire
FAKE -1.68272667818 jewish
FAKE -1.65334397724 youtube
FAKE -1.6241703128 pipeline
REAL 4.78064061698 said
REAL 2.68703967567 tuesday
REAL 2.48309800829 gop
REAL 2.45710670245 islamic
REAL 2.44326123901 says
REAL 2.29424417889 cruz
REAL 2.29144842597 marriage
REAL 2.20500735471 candidates
REAL 2.19136552672 conservative
REAL 2.18030834903 monday
REAL 2.05688105375 attacks
REAL 2.03476457362 rush
REAL 1.9954523319 continue
REAL 1.97002430576 friday
REAL 1.95034103105 convention
REAL 1.94620720989 sen
REAL 1.91185661202 jobs
REAL 1.87501303774 debate
REAL 1.84059602241 presumptive
REAL 1.80111133252 say
REAL 1.80027216061 sunday
REAL 1.79650823765 march
REAL 1.79229792108 paris
REAL 1.74587899553 security
REAL 1.69585506276 conservatives
REAL 1.68860503431 recounts
REAL 1.67424302821 deal
REAL 1.67343398121 campaign
REAL 1.66148582079 fox
REAL 1.61425630518 attack
你也可以仅用几行Python就可以很明显地做到这一点, 方法是将系数压缩到功能中, 并查看列表的顶部和底部。
在[31]中:
feature_names = tfidf_vectorizer.get_feature_names()
在[32]中:
### Most real
sorted(zip(clf.coef_[0], feature_names), reverse=True)[:20]
出[32]:
[(-6.2573612147015822, 'trump'), (-6.4944530943126777, 'said'), (-6.6539784739838845, 'clinton'), (-7.0379446628670728, 'obama'), (-7.1465399833812278, 'sanders'), (-7.2153760086475112, 'president'), (-7.2665628057416169, 'campaign'), (-7.2875931446681514, 'republican'), (-7.3411184585990643, 'state'), (-7.3413571102479054, 'cruz'), (-7.3783124419854254, 'party'), (-7.4468806724578904, 'new'), (-7.4762888011545883, 'people'), (-7.547225599514773, 'percent'), (-7.5553074094582335, 'bush'), (-7.5801506339098932, 'republicans'), (-7.5855405012652435, 'house'), (-7.6344781725203141, 'voters'), (-7.6484824436952987, 'rubio'), (-7.6734836186463795, 'states')]在[33]中:
### Most fake
sorted(zip(clf.coef_[0], feature_names))[:20]
出[33]:
[(-11.349866225220305, '0000'), (-11.349866225220305, '000035'), (-11.349866225220305, '0001'), (-11.349866225220305, '0001pt'), (-11.349866225220305, '000km'), (-11.349866225220305, '0011'), (-11.349866225220305, '006s'), (-11.349866225220305, '007'), (-11.349866225220305, '007s'), (-11.349866225220305, '008s'), (-11.349866225220305, '0099'), (-11.349866225220305, '00am'), (-11.349866225220305, '00p'), (-11.349866225220305, '00pm'), (-11.349866225220305, '014'), (-11.349866225220305, '015'), (-11.349866225220305, '018'), (-11.349866225220305, '01am'), (-11.349866225220305, '020'), (-11.349866225220305, '023')]因此, 很明显, 某些词语可能在顶级假冒特征中显示出政治意图和出处(例如”公司”和”公司”一词)。
同样, 真实新闻数据更经常使用动词”说”的形式, 这可能是因为报纸和大多数新闻出版物直接引用了消息来源(“德国总理安格拉·默克尔说过……”)。
要从当前分类器中提取完整列表并查看每个标记(或轻松比较各个分类器之间的标记), 可以像这样轻松地将其导出。
在[34]中:
tokens_with_weights = sorted(list(zip(feature_names, clf.coef_[0])))
Intermezzo:HashingVectorizer
有时用于文本分类的另一个矢量化程序是HashingVectorizer。 HashingVectorizers需要较少的内存, 并且速度更快(因为它们稀疏并且使用哈希而不是令牌), 但是更难以自省。如果你有兴趣, 可以在scikit-learn文档中阅读有关使用HashingVectorizer的优缺点的更多信息。
你可以尝试一下, 并将其结果与其他矢量化器进行比较。与使用MultinomialNB的TF-IDF矢量化器相比, 它的性能相当好(由于CountVectorizers性能更好的相同原因, 这在一定程度上是可以预期的), 但与采用Passive Aggressive线性算法的TF-IDF矢量化器却不一样。
在[35]中:
hash_vectorizer = HashingVectorizer(stop_words='english', non_negative=True)
hash_train = hash_vectorizer.fit_transform(X_train)
hash_test = hash_vectorizer.transform(X_test)
在[36]中:
clf = MultinomialNB(alpha=.01)
在[37]中:
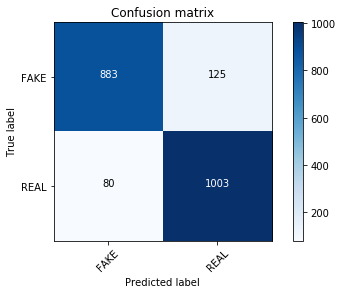
clf.fit(hash_train, y_train)
pred = clf.predict(hash_test)
score = metrics.accuracy_score(y_test, pred)
print("accuracy: %0.3f" % score)
cm = metrics.confusion_matrix(y_test, pred, labels=['FAKE', 'REAL'])
plot_confusion_matrix(cm, classes=['FAKE', 'REAL'])
accuracy: 0.902
Confusion matrix, without normalization
在[38]中:
clf = PassiveAggressiveClassifier(n_iter=50)
在[39]中:
clf.fit(hash_train, y_train)
pred = clf.predict(hash_test)
score = metrics.accuracy_score(y_test, pred)
print("accuracy: %0.3f" % score)
cm = metrics.confusion_matrix(y_test, pred, labels=['FAKE', 'REAL'])
plot_confusion_matrix(cm, classes=['FAKE', 'REAL'])
accuracy: 0.921
Confusion matrix, without normalization
总结
那么你的假新闻分类器实验成功了吗?当然不。
但是你确实可以使用一个新的数据集, 测试一些NLP分类模型, 并反思它们的成功程度如何?是。
就像从一开始就期望的那样, 用简单的词袋或TF-IDF向量定义假新闻是一种过于简化的方法。尤其是对于充满噪声令牌的多语言数据集。如果你不看模型实际学习了什么, 你可能会认为模型学到了一些有意义的东西。因此, 请记住:总是对你的模型进行自省(尽你所能!)。
如果你在我可能错过的数据中找到其他趋势, 我会很好奇。我将在博客中跟进有关不同分类器如何根据重要功能进行比较的文章。如果你花一些时间进行研究并发现任何有趣的东西, 请随时在评论中分享你的发现和笔记, 或者你随时可以在Twitter上与我们联系(我是@kjam)。
希望你能和我一起探索新的NLP数据集玩得开心!
评论前必须登录!
注册