 srcmini
srcmini本文概述
在学习期间, 我有机会从事了多个机器学习研究项目。这些项目的范围从研究概率模型到自然语言处理中的更实际场景。在我所做的工作中, 一个共同的要素是明确定义的问题的可用性和大量干净的数据集。
在过去的一年中, 我一直在Microsoft担任数据科学家, 以解决企业客户的问题。从跨行业工作中获得的经验从数据科学的角度和问题解决的角度以多种方式测试了我的技能。通常, 大部分时间用于定义问题, 创建数据集和清理数据, 而大型数据集几乎总是很难获得。

不同研究领域中使用的数据集大小示例。资源
在这篇博客文章中, 我分享了一些在”野外”进行数据科学项目时可能会学到的教训和陷阱。这些陷阱几乎总是存在的, 通常需要”创意”才能解决。
陷阱
描述性, 预测性和规范性分析
有几种不同的方式可以利用数据来改善业务流程。你通常从客户那里获得的任务是”解决业务问题X”。一个具体的例子是”提高营销活动的盈利能力”。
一个常见的陷阱是不能按”正确”的顺序解决问题。如果要改进流程, 则需要完全理解它, 甚至要考虑使其一部分自动化。客户通常对自己的数据了解有限, 没有数据科学经验。因此, 从数据科学的角度清楚地向他们解释不同的选择是非常重要的。
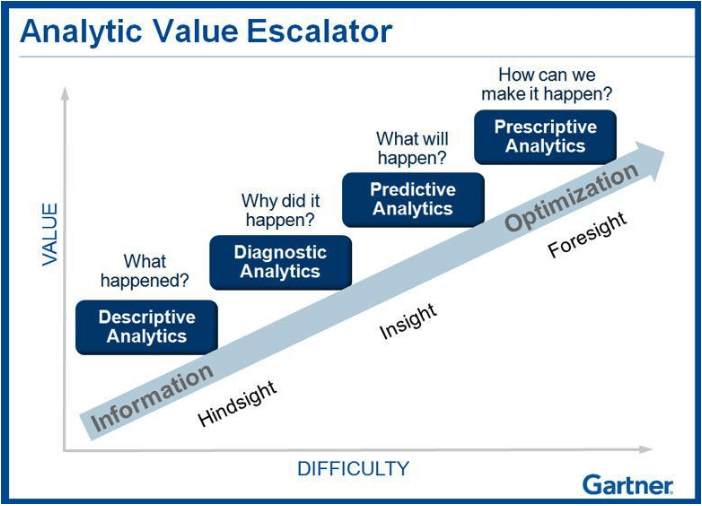
数据分析的价值:从描述性到描述性分析源
通常, 你通过清理和分析数据来启动项目。当你旨在构建数据摘要并尝试了解数据中不同变量之间的关系时, 将使用”描述性和诊断性”分析术语。你可以建立可视化并使用(无人监督的)机器学习技术来聚类数据点或查找相关变量。根据流程的结果, 你可以例如构建报告或仪表板, 其中列出并调查了对业务问题有用的一组KPI。使用市场营销活动, 你可以将销售和市场营销数据关联起来, 以了解市场活动成功的原因。结论(例如, 较低的价格导致更多的销售)可能并不总是”火箭科学”, 但它们可以使客户使用其数据来验证其假设。此外, 它还允许他们发现异常行为以及它们是否具有正确的数据类型。
预测性和规范性分析是关于预测未来并根据这些预测采取行动。使用预测分析, 你可以获取历史数据, 并建立机器学习模型来预测未来的数据点(在一定的误差范围内)。在市场营销中, 新颖的营销理念通常通过使用预测模型估算预期销售额来进行验证。通过完成之前的描述和诊断阶段, 你应该对性能方面有一个清晰的认识。如果数据质量不足以构建健壮的模型, 则可以将其标记给客户, 你可以使用他们提供的数据来备份索赔。
借助规范性分析, 目标是根据预测采取行动, 并优化流程的某些方面。你可以例如验证广告系列的想法, 而不必验证建立可以生成”未来最佳广告系列”列表的优化引擎。构建此系统需要大量高质量的数据。请注意, 数据科学是关于承诺不足和交付过多的全部内容, 因此, 从小处着手, 然后再构建大块!
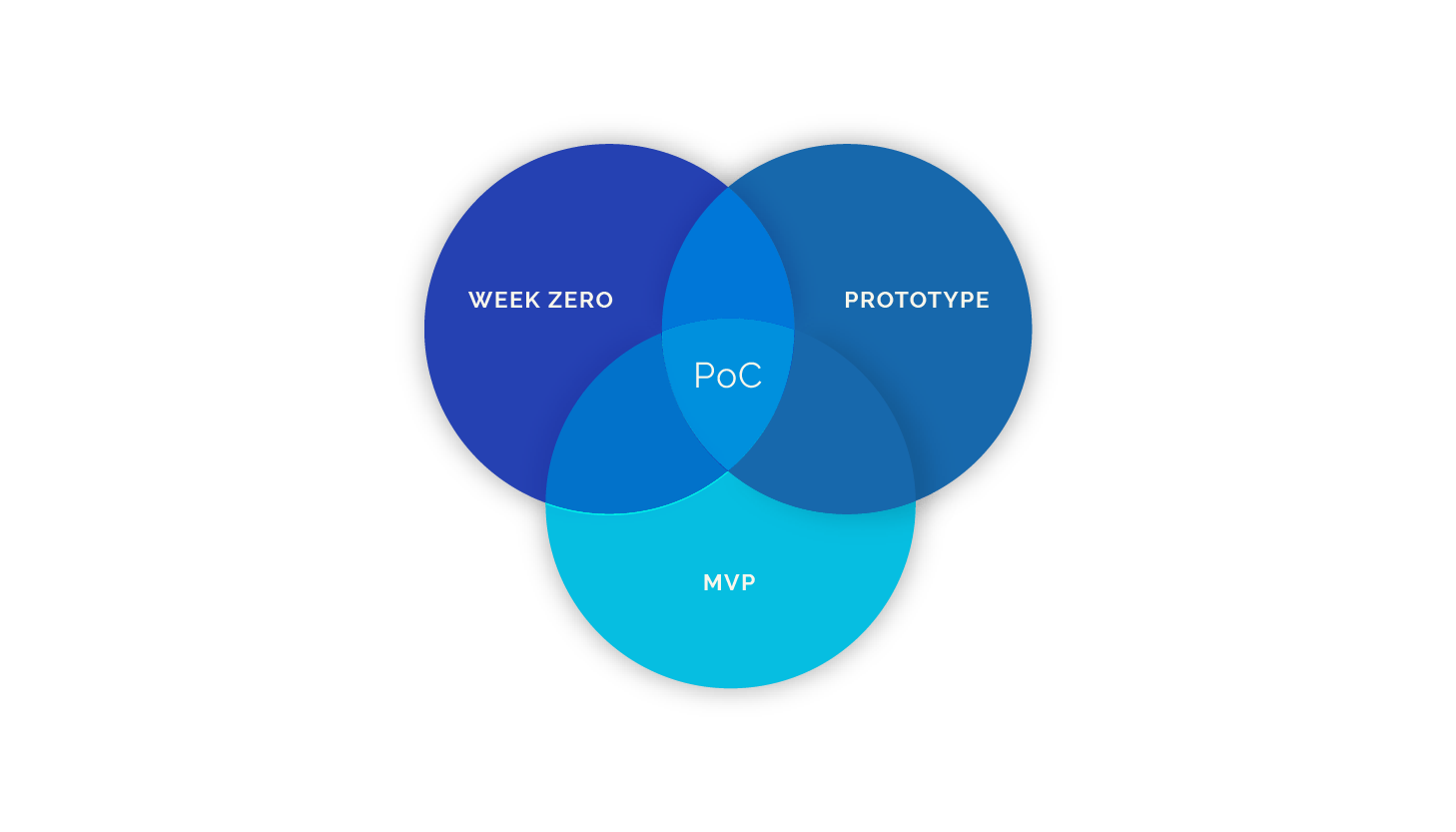
概念验证与飞行员
客户通常喜欢使用概念验证来研究”数据科学”的可能性。通常, 这意味着他们提供了数据的子集, 并且他们希望确定一些初步结果。尽管客户通常理解你使用PoC不能获得良好的性能, 但这仍然是常见的要求。但是, PoC的缺点是数据的子集通常不能代表完整的数据集和问题。使用PoC可能会获得非常好的性能, 但是你可能无法在完整的数据集上复制它。客户通过例如仅关注很小的时间段, 这可能会严重影响PoC模型。
资源
如果客户要进行试验, 更好的选择是与飞行员合作。在试验中, 你将使用完整的数据集, 并进行数据科学管道的初始迭代(数据清理, 建模等)。使用完整的数据集可以减轻项目中的很多风险。模型的性能仍然不是最佳的, 因为你只有有限的时间, 但是至少你应该能够获得代表性的图片。
代表性数据集
尽管此陷阱与上一个陷阱类似, 但并不相同。特别是如果你使用非结构化数据(例如图像, 文本数据等), 则在开始项目之前, 客户可能已经收集了数据。数据集的关键但经常被忽略的要素是它是否代表用例。如果需要收集数据集, 则应采用与最终使用模型相同的方式进行。
例如, 如果要使用计算机视觉进行库存管理, 则在要使用模型的商店或冰箱中拥有对象的图像非常重要。目录类型的图像不代表用例, 因此无法建立可靠的模型。该模型必须学习鲁棒的功能, 以便检测环境中的对象。

很难想象最终用户的冰箱会如此干净!

左侧的图像不能很好地代表右侧的用例!
高性能和过拟合
当你在问题开始时获得极佳的性能(> 90%)时, 数据科学的黄金法则就是令人怀疑。在项目开始时的良好性能可能表明”泄漏”变量或”泄漏”数据集。泄漏变量是与目标变量高度相关的变量, 在推断时不大可能使用。如果目标是预测销售, 则你将无法使用其他产品的销售作为功能, 因为该数据将不可用。当数据集仅反映特定(时间)段时, 就会发生”泄漏”数据集。通常, 需要解决的问题要容易得多, 而且该模型很可能适合数据中的噪声, 而不是实际信号。
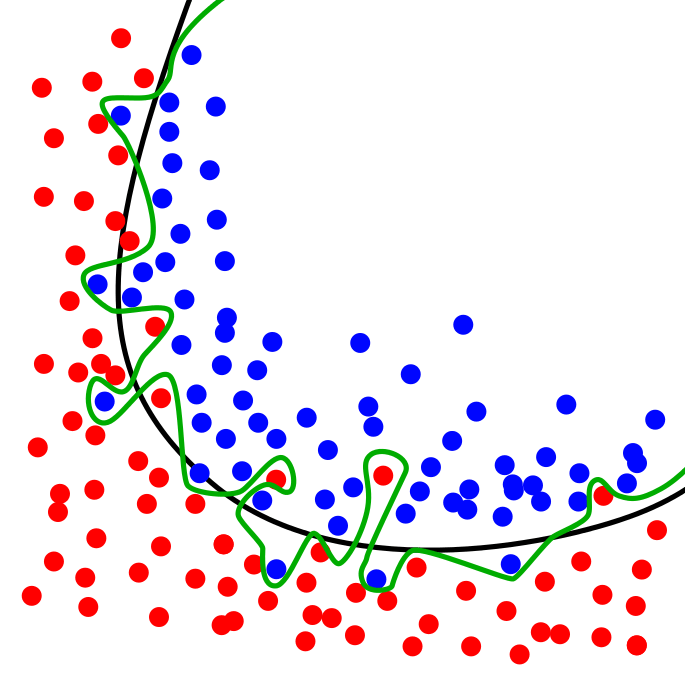
机器学习中最简单的事情就是过拟合!资源
高性能的模型很棒, 但前提是它在全新的随机数据集上的性能同样出色!
将相关性解释为因果关系
我非常喜欢这篇关于统计谬论的博客文章。将相关性解释为因果关系只是经常发生的错误类型之一, 而深入了解其背后的统计数据是关键。
模型和数据的可解释性
如果客户使用模型作为行动的基础, 他们将始终喜欢可解释和可理解的解决方案。在这篇博客文章中, 我深入探讨了模型可解释性是关键的原因。我还更深入地介绍了可以使用的各种技术。
总结
我只触及了6个潜在的数据科学陷阱, 但我坚信在过去的一年中我可能犯了更多的错误。如果你有数据科学项目的经验, 并且想分享你遇到的常见问题, 我们将很乐意在评论中阅读它们。如果你想接收我的博客文章的更新, 请在Medium或Twitter上关注我!
如果你有兴趣了解有关数据科学的更多信息, 请查看srcmini的R入门和Python入门课程。
评论前必须登录!
注册