 srcmini
srcmini本文概述
在本教程中, 你将学习如何在python中使用非常独特的库:tpot。该库之所以独特, 是因为它可以自动执行整个机器学习管道, 并为你提供性能最佳的机器学习模型。更具体地说, 你将学习:
- 自动化机器学习背后的想法
- TPOT如何使用遗传编程来选择最佳的机器学习模型
- 在Python中对数据集使用TPOT
- TPOT的局限性
让我们开始吧!
介绍
解决机器学习问题之前, 你需要考虑很多组件, 其中一些组件包括数据准备, 特征选择, 特征工程, 模型选择和验证, 超参数调整等。从理论上讲, 你可以找到并应用大量的这些组件中的每个组件使用不同的技术, 但对于不同的数据集, 它们的性能可能有所不同。面临的挑战是找到性能最佳的技术组合, 以便最大程度地减少预测中的误差。这是当今人们致力于开发Auto-ML算法和平台的主要原因, 这样任何人都可以在没有任何机器学习专业知识的情况下构建模型而无需花费大量时间或精力。一个这样的平台可用作python库:TPOT。你可以将TPOT视为你的数据科学助手。 TPOT是python自动机器学习工具, 可使用遗传编程来优化机器学习管道。通过智能地探索数千条可能的管道以找到最适合你的数据的管道, 它将自动化机器学习中最繁琐的部分。
from IPython.core.display import Image
Image(filename="/home/manishpathak/srcmini/tpot/tpot-ml-pipeline.png", width=800, height=800)

TPOT完成搜索后, 它将为你提供找到的最佳管道的Python代码, 因此你可以从那里修改管道。
安装
要在系统上安装tpot, 可以在命令行终端上运行命令sudo pip install tpot或查看此链接。 tpot建立在几个现有的Python库之上, 包括numpy, scipy, scikit-learn, DEAP, update_checker, tqdm, stopit, pandas。大多数必需的Python软件包都可以通过Anaconda Python发行版安装, 也可以单独安装。 (可选)如果你希望tpot使用eXtreme Gradient Boosting模型, 也可以安装XGBoost。
基因编程
有了正确的数据, 计算能力和机器学习模型, 你可以找到任何问题的解决方案, 但是要知道使用哪种模型可能对你来说是一个挑战, 因为决策树, SVM, KNN等种类繁多。基因编程可以发挥很大的作用并提供帮助。遗传算法的灵感来自自然选择的达尔文式过程, 它们被用来为计算机科学中的优化和搜索问题生成解决方案。
广义上讲, 遗传算法具有三个属性:
- 选择:对于给定问题和适应度函数, 你有很多可能的解决方案。在每次迭代中, 你都要评估如何使每个解决方案适合你的适应度函数。
- 交叉:然后选择最适合的交叉并执行交叉以创建新种群。
- 变异:你可以带这些孩子并进行一些随机修改来变异他们, 然后重复该过程, 直到获得最合适或最佳的解决方案为止。
遗传编程本身是计算机科学中的一个大话题, 但是如果你想更深入地研究遗传算法, 请观看此视频系列。
但是, 这一切如何适合数据科学?
好吧, 事实证明, 选择正确的机器学习模型和该模型的所有最佳超参数本身就是一个可以使用遗传编程的优化问题。构建在scikit-learn之上的Python库tpot使用遗传编程来优化你的机器学习管道。例如, 在机器学习中, 准备好数据后, 你需要知道要输入什么特征到模型中, 以及如何构造这些特征。一旦拥有了这些功能, 就可以将它们输入到模型中进行训练, 然后调整超参数以获得最佳结果。 TPOT无需自己通过反复试验来完成所有这些工作, 而是通过基因编程为你自动执行这些步骤, 并在完成后为你输出最佳代码。
为了进一步理解, 你将练习在开源数据集中使用tpot库。你将使用的数据集是MAGIC Gamma望远镜数据集。使用成像技术生成数据以模拟高能伽玛粒子在地面大气奇伦科夫伽玛望远镜中的配准。要获取有关数据集描述的完整详细信息, 请查看此链接。数据集具有以下属性/特征:
- fLength:连续的#个椭圆长轴[mm]
- fWidth:连续的#个椭圆短轴[mm]
- fSize:连续#所有像素的内容总和的10个对数[在#phot中]
- fConc:连续#两个最高像素之和与fSize [ratio]的比率
- fConc1:最高像素与fSize的连续#比率[比率]
- fAsym:从最高像素到中心的连续#距离, 投影到主轴上[mm]
- fM3Long:连续#沿主轴的第三矩的第三个根[mm]
- fM3Trans:连续#沿短轴的第三弯矩的第三个根[mm]
- fAlpha:主轴的连续#角度与矢量到原点的角度[deg]
- fDist:连续#从原点到椭圆中心的距离[mm]
- 类别:g, h#伽玛(信号), 强子(背景)(目标变量)
目标是根据提供的属性将观测分类为伽玛(即所需信号)或强子(即背景噪声)。
你将从导入pandas和numpy库开始以分别读取数据并对其进行计算。
import pandas as pd
import numpy as np
使用pandas read_csv()函数将数据集作为DataFrame读取。另外, 由于数据集还没有列名, 因此指定参数header = None。
telescope_data=pd.read_csv('https://archive.ics.uci.edu/ml/machine-learning-databases/magic/magic04.data', header=None)
使用head()方法检查DataFrame的内容。
telescope_data.head()
要给DataFrame的列命名, 可以使用pandas DataFrame上的属性列, 并将其分配给包含列名的列表。
telescope_data.columns = ['fLength', 'fWidth', 'fSize', 'fConc', 'fConcl', 'fAsym', 'fM3Long', 'fM3Trans', 'fAlpha', 'fDist', 'class']
telescope_data.head()
现在, 你在DataFrame中也具有列名。
要获取有关DataFrame的必要信息, 例如每列中的值数, 数据类型, 计数, 平均值等, 可以使用pandas info()和describe()方法。
telescope_data.info()
<class 'pandas.core.frame.DataFrame'>
RangeIndex: 19020 entries, 0 to 19019
Data columns (total 11 columns):
fLength 19020 non-null float64
fWidth 19020 non-null float64
fSize 19020 non-null float64
fConc 19020 non-null float64
fConcl 19020 non-null float64
fAsym 19020 non-null float64
fM3Long 19020 non-null float64
fM3Trans 19020 non-null float64
fAlpha 19020 non-null float64
fDist 19020 non-null float64
class 19020 non-null object
dtypes: float64(10), object(1)
memory usage: 1.6+ MB
telescope_data.describe()
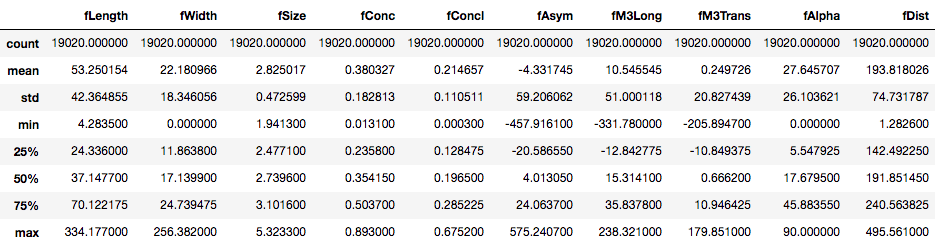
事实证明, DataFrame中的所有功能本质上都是连续的。但是目标变量/功能类别是分类的。你可以使用value_counts()方法检查目标变量中每个类的计数。
telescope_data['class'].value_counts()
g 12332
h 6688
Name: class, dtype: int64
在开始避免对数据进行任何类型的排序之前, 随机地随机整理数据通常是一个好主意。你可以使用numpy的random和permutation()函数重新排列DataFrame中的数据。要在随机播放后重设索引号, 请使用带有drop = True作为参数的reset_index()方法。
telescope_shuffle=telescope_data.iloc[np.random.permutation(len(telescope_data))]
tele=telescope_shuffle.reset_index(drop=True)
tele.head()
在使用tpot之前, 必须对DataFrame中的类别变量进行标记。要了解有关标记分类变量的更多信息, 请查看本教程。在这里, 只有目标变量类是分类特征, 因此应对该列进行处理。你将用数值0替换g类(信号), 并用数值1替换h类(背景)。这可以通过map()函数来实现, 其参数为字典, 该字典包含分别对应的class类的映射。目标变量。
tele['class']=tele['class'].map({'g':0, 'h':1})
tele.head()
现在, 将需要预测的类标签存储在单独的变量tele_class中。
tele_class = tele['class'].values
使用tpot之前, 你还应该进行价值缺失处理。要按列检查缺失值的数量, 可以执行以下操作:
pd.isnull(tele).any()
fLength False
fWidth False
fSize False
fConc False
fConcl False
fAsym False
fM3Long False
fM3Trans False
fAlpha False
fDist False
class False
dtype: bool
该数据集没有任何缺失值。请注意, 在缺少值的数据集中, 你可以使用dropna()方法删除行/列, 或者使用fillna()方法将缺少的值替换为一些虚拟值。例如, 以下代码块将NA值替换为虚拟值-999。
tele = tele.fillna(-999)
现在, 你将DataFrame分为训练集和测试集, 就像进行任何类型的机器学习建模时一样。你可以通过sklearn的cross_validation train_test_split进行此操作。参数是tele.index作为DataFrame的索引, train_size = 0.75保留训练集中的数据的75%, test_size = 0.25保留其余25%的数据在测试集中的数据, strateify = tele_class类标签在数据集中的值。请注意, 验证集只是为了让我们对测试集错误有所了解。在这里, 它与测试集保持相同。
from sklearn.cross_validation import train_test_split
training_indices, validation_indices = training_indices, testing_indices = train_test_split(tele.index, stratify = tele_class, train_size=0.75, test_size=0.25)
你可以使用size属性检查训练集和验证集的大小。
training_indices.size, validation_indices.size
(14265, 4755)
现在是时候使用tpot库为我们提出针对此二进制分类问题的最佳管道了。为此, 你必须从tpot库导入TPOTClassifier类。如果这是一个回归问题, 则应该导入TPOTRegressor类。
TPOTClassifier具有各种各样的参数, 你可以在此处阅读有关它们的全部信息。但是, 你必须知道的最著名的是:
- generations:运行管道优化过程的迭代次数。默认值为100。
- 人口大小:每一代保留在基因编程人口中的个体数量。默认值为100。
- offspring_size:每个遗传编程世代中要产生的后代数量。默认值为100。
- variant_rate:遗传编程算法的突变率, 范围为[0.0, 1.0]。此参数告诉GP算法有几条管道可对每一代应用随机更改。默认值为0.9
- crossover_rate:遗传编程算法的交叉率在[0.0, 1.0]范围内。此参数告诉遗传编程算法每一代”繁殖”多少条管道。
- 评分:用于评估给定管道质量的分类问题(例如准确性, average_precision, roc_auc, 召回率等)的函数。默认值为准确性。
- cv:评估管道时使用的交叉验证策略。预设值为5。
- random_state:TPOT中使用的伪随机数生成器的种子。使用此参数可确保每次对带有该种子的相同数据集运行TPOT时, 都能获得相同的结果。
另请注意, mutation_rate + crossover_rate不能超过1.0。
在这里, 你将使用tpot, 其generations = 5, 其余参数为默认值。参数verbosity = 2表示TPOT在运行时传达了多少信息。
然后, 将使用训练集(不包含目标列)和目标列作为参数来调用fit()方法。
请注意, 在下面的单元格中运行代码将需要几个小时才能完成。使用给定的TPOT设置(5代, 人口总数为100), TPOT将在完成之前评估500个管线配置。为了将这个数字放在上下文中, 请考虑针对机器学习算法的500个超参数组合的网格搜索以及该网格搜索将花费多长时间。这是500种模型配置, 需要进行5倍交叉验证才能进行评估, 这意味着大约2500个模型可以在一格搜索中拟合并评估训练数据。这是一个耗时的过程!稍后, 你将了解更多可传递给TPOTClassifier的参数, 以控制TPOT完成的执行时间。
from tpot import TPOTClassifier
from tpot import TPOTRegressor
tpot = TPOTClassifier(generations=5, verbosity=2)
tpot.fit(tele.drop('class', axis=1).loc[training_indices].values, tele.loc[training_indices, 'class'].values)
Optimization Progress: 33%|███▎ | 200/600 [41:43<1:51:41, 16.75s/pipeline]
Generation 1 - Current best internal CV score: 0.880266061124
Optimization Progress: 50%|█████ | 300/600 [1:14:37<46:57, 9.39s/pipeline]
Generation 2 - Current best internal CV score: 0.880266061124
Optimization Progress: 67%|██████▋ | 400/600 [1:59:17<2:21:21, 42.41s/pipeline]
Generation 3 - Current best internal CV score: 0.880266061124
Optimization Progress: 84%|████████▎ | 501/600 [3:01:12<1:02:16, 37.74s/pipeline]
Generation 4 - Current best internal CV score: 0.881597992166
Generation 5 - Current best internal CV score: 0.881597992166
Best pipeline: GradientBoostingClassifier(RobustScaler(PolynomialFeatures(input_matrix, degree=2, include_bias=False, interaction_only=False)), learning_rate=0.1, max_depth=6, max_features=0.6000000000000001, min_samples_leaf=12, min_samples_split=3, n_estimators=100, subsample=0.55)
TPOTClassifier(config_dict={'sklearn.ensemble.GradientBoostingClassifier': {'max_features': array([0.05, 0.1 , 0.15, 0.2 , 0.25, 0.3 , 0.35, 0.4 , 0.45, 0.5 , 0.55, 0.6 , 0.65, 0.7 , 0.75, 0.8 , 0.85, 0.9 , 0.95, 1. ]), 'learning_rate': [0.001, 0.01, 0.1, 0.5, 1.0], 'min_samples_leaf': [1, 2, 3, 4, 5, 6, 7... 0.6 , 0.65, 0.7 , 0.75, 0.8 , 0.85, 0.9 , 0.95, 1. ])}, 'sklearn.preprocessing.RobustScaler': {}}, crossover_rate=0.1, cv=5, disable_update_check=False, early_stop=None, generations=5, max_eval_time_mins=5, max_time_mins=None, memory=None, mutation_rate=0.9, n_jobs=1, offspring_size=100, periodic_checkpoint_folder=None, population_size=100, random_state=None, scoring=None, subsample=1.0, verbosity=2, warm_start=False)
在上面, 计算了5个世代, 每个世代都给出了训练模型上拟合模型的训练效率。显而易见, 最好的管道是CV准确度得分为88.16%的管道。产生此结果的模型是管道, 由诸如PloynomialFeatures之类的预处理技术组成, 然后由RobustScaler组成, 后者将合成特征添加到输入数据并对其进行归一化, 然后由Gradient Boosting分类器加以利用以形成最终预测。你还可以注意到, tpot还提供了各种超参数值, 例如learning_rate, max_depth等, 以及分类器。
接下来, 计算测试误差以进行验证。
tpot.score(tele.drop('class', axis=1).loc[validation_indices].values, tele.loc[validation_indices, 'class'].values)
0.885173501577287
可以看出, 测试精度为88.51%。
最后, 你可以告诉TPOT使用导出功能将用于优化管道的相应Python代码导出到文本文件:
tpot.export('tpot_MAGIC_Gamma_Telescope_pipeline.py')
True
## This is the pipeline that tpot generated: tpot_MAGIC_Gamma_Telescope_pipeline.py
import numpy as np
import pandas as pd
from sklearn.ensemble import GradientBoostingClassifier
from sklearn.model_selection import train_test_split
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import PolynomialFeatures, RobustScaler
# NOTE: Make sure that the class is labeled 'target' in the data file
tpot_data = pd.read_csv('PATH/TO/DATA/FILE', sep='COLUMN_SEPARATOR', dtype=np.float64)
features = tpot_data.drop('target', axis=1).values
training_features, testing_features, training_target, testing_target = \
train_test_split(features, tpot_data['target'].values, random_state=42)
# Score on the training set was:0.881597992166
exported_pipeline = make_pipeline(
PolynomialFeatures(degree=2, include_bias=False, interaction_only=False), RobustScaler(), GradientBoostingClassifier(learning_rate=0.1, max_depth=6, max_features=0.6, min_samples_leaf=12, min_samples_split=3, n_estimators=100, subsample=0.55)
)
exported_pipeline.fit(training_features, training_target)
results = exported_pipeline.predict(testing_features)
那不是很棒吗?无需调整许多参数和选项即可获得最佳模型, TPOT不仅为你提供了有关最佳模型的信息, 还为你提供了有效的代码!
如前所述, 上一次TPOT运行需要几个小时才能完成。好了, 你可以指定某些参数来控制TPOT的执行时间, 但需要权衡取舍。由于你将限制TPOT的执行时间, 因此TPOT将无法探索所有可能的管道, 因此TPOT在受限时间限制结束时建议的最佳模型可能不是该数据集的最佳模型。但是, 如果给出足够的时间, 它将稍微接近最佳模型。一些参数是:
- max_time_mins:TPOT必须优化管道多少分钟。如果不是None, 则此设置将覆盖generations参数, 并允许TPOT运行, 直到经过max_time_mins分钟。
- max_eval_time_mins:TPOT需要评估单个管道多少分钟。将此参数设置为更高的值将使TPOT能够评估更复杂的管道, 但也将允许TPOT运行更长的时间。使用此参数有助于防止TPOT在评估耗时的管道上浪费时间。预设值为5。
- early_stop:TPOT检查了几代, 优化过程是否没有改善。如果给定的世代数没有改善, 则结束优化过程。
- n_jobs:在TPOT优化过程中并行用于评估管道的过程数。设置n_jobs = -1将使用计算机上可用的尽可能多的内核。请注意, 在同一台计算机上使用多种方法可能会导致大型数据集的内存问题。预设值为1。
- 子样本:在TPOT优化过程中使用的训练样本的分数。必须在(0.0, 1.0]范围内。默认值为1。
仅出于练习目的, 你将再次使用其他参数max_time_mins = 2和max_eval_time_mins = 0.04来运行TPOT, 但这一次是使用人口总数减小为15。
tpot = TPOTClassifier(verbosity=2, max_time_mins=2, max_eval_time_mins=0.04, population_size=15)
tpot.fit(tele.drop('class', axis=1).loc[training_indices].values, tele.loc[training_indices, 'class'].values)
Optimization Progress: 42pipeline [00:42, 1.17s/pipeline]
Generation 1 - Current best internal CV score: 0.86119902629
Optimization Progress: 64pipeline [01:03, 1.04s/pipeline]
Generation 2 - Current best internal CV score: 0.86119902629
Optimization Progress: 83pipeline [01:21, 1.14s/pipeline]
Generation 3 - Current best internal CV score: 0.861689811492
Optimization Progress: 104pipeline [01:45, 1.03pipeline/s]
Generation 4 - Current best internal CV score: 0.861759642796
2.03228221667 minutes have elapsed. TPOT will close down.
TPOT closed prematurely. Will use the current best pipeline.
Best pipeline: XGBClassifier(RobustScaler(SelectPercentile(input_matrix, percentile=85)), learning_rate=0.1, max_depth=2, min_child_weight=4, n_estimators=100, nthread=1, subsample=0.1)
TPOTClassifier(config_dict={'sklearn.ensemble.GradientBoostingClassifier': {'max_features': array([0.05, 0.1 , 0.15, 0.2 , 0.25, 0.3 , 0.35, 0.4 , 0.45, 0.5 , 0.55, 0.6 , 0.65, 0.7 , 0.75, 0.8 , 0.85, 0.9 , 0.95, 1. ]), 'learning_rate': [0.001, 0.01, 0.1, 0.5, 1.0], 'min_samples_leaf': [1, 2, 3, 4, 5, 6, 7... 0.6 , 0.65, 0.7 , 0.75, 0.8 , 0.85, 0.9 , 0.95, 1. ])}, 'sklearn.preprocessing.RobustScaler': {}}, crossover_rate=0.1, cv=5, disable_update_check=False, early_stop=None, generations=1000000, max_eval_time_mins=0.04, max_time_mins=2, memory=None, mutation_rate=0.9, n_jobs=1, offspring_size=15, periodic_checkpoint_folder=None, population_size=15, random_state=None, scoring=None, subsample=1.0, verbosity=2, warm_start=False)
如你所见, 现在在指定的时间范围内性能最佳的分类器是XGBoost, 其中SelectPercentile()和RobustScaler()作为预处理步骤。
局限性
- TPOT可能需要很长时间才能完成搜索
运行TPOT并不像在数据集中拟合一个模型那么简单。它正在考虑在具有大量预处理步骤(缺失值插补, 缩放, PCA, 特征选择等)的管线中使用多种机器学习算法(随机森林, 线性模型, SVM等), 以及所有的超参数。模型和预处理步骤, 以及在管道中集成或堆叠算法的多种方法。这就是为什么通常需要很长时间才能执行并且不适用于大型数据集的原因。
- TPOT可以为同一数据集推荐不同的解决方案
如果你使用相当复杂的数据集或在短时间内运行TPOT, 则不同的TPOT运行可能会产生不同的管道建议。当两个TPOT运行建议使用不同的管道时, 这意味着TPOT运行由于时间不足而没有收敛, 或者多个管道在你的数据集上几乎表现相同。
总结
欢呼!你已经到了本教程的结尾。你首先介绍了自动化机器学习平台背后的想法。然后, 你探讨了遗传编程以及TPOT如何使用它来自动化机器学习管道构建过程。你还练习了在数据集中使用Python中的TPOT库, 并获得了有关其提供的功能的知识。如果你打算将来使用TPOT, 强烈建议你查看其出色的文档。探索愉快!
如果你想了解有关使用Python进行机器学习的更多信息, 请参加srcmini的Python基于树型模型的机器学习课程。
以下网页用作编写本教程的资源。
- 分类
- 对AutoML软件的期望
评论前必须登录!
注册