 srcmini
srcmini本文概述
目录
- 什么是强化学习?
- 强化学习与其他
- 强化学习的直觉
- 基本概念和术语
- 强化学习的工作原理
- 简单实施
- 总结
- 参考和链接
什么是强化学习?
形式上的强化学习是一种机器学习的方法, 其中, 软件代理学习在导致其最大回报的环境中执行某些动作。它通过探索和利用它所获得的知识, 并通过反复尝试以最大化奖励来学习。
强化学习与其他
除了强化学习之外, 机器学习的方法如下所示-
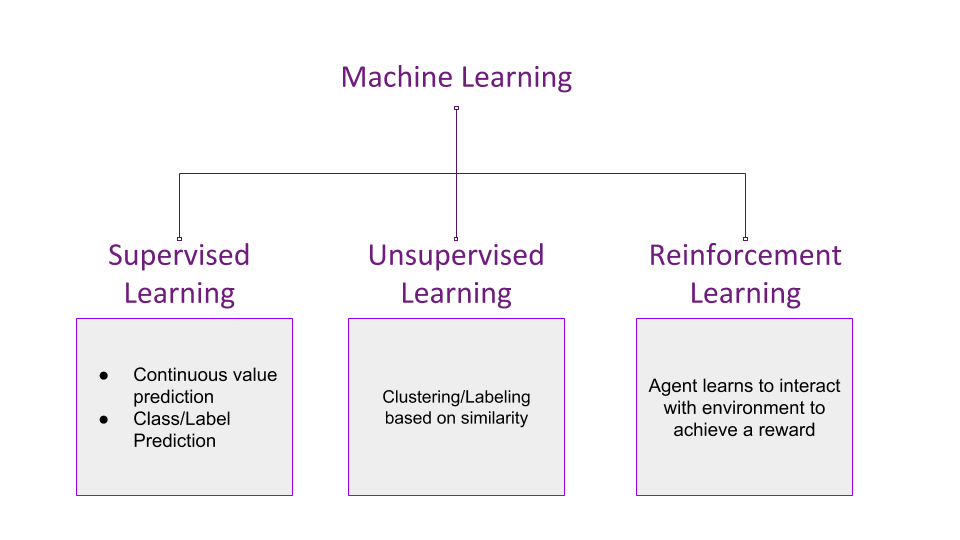
可以得出结论, 尽管监督学习根据训练来预测连续的范围值或离散的标签/类, 但它会从带有提供的标签或值的示例中接受训练。无监督学习尝试根据样本的相似性将样本合并在一起, 并确定离散的聚类。
另一方面, 强化学习是无监督学习的一个子集, 其学习效果截然不同。它采用”因果”方法。
强化学习的直觉
让我们尝试通过一个示例来理解先前陈述的正式定义-
想象一下, 你应该在漆黑的夜晚没有火炬的情况下越过未知的田野。田间可能有坑和石头, 这些坑的位置对你来说是陌生的。有一个简单的规则-如果你掉入一个洞或撞到一块岩石, 则必须从初始位置重新开始。
- 你开始盲目向前走, 只计算要执行的步骤数。 x步之后, 你陷入了一个坑。自从走了那么多步骤以来, 你的奖励是x点。
- 你从初始位置重新开始, 但是经过x步后, 你向左/向右绕行, 然后再次向前移动。你经过y步就打了石头。这次你的报酬是y, 大于x。你决定再次走这条路, 但要更加谨慎。
- 当你再次开始时, 你在x步之后绕行, 在y步之后绕行, 并在z步之后设法落入另一个凹坑。这次的奖励是z点, 大于y, 你认为这是再次采取的好方法。
- 再次重新启动, 在x, y和z步骤之后绕道而行, 到达字段的另一侧。因此, 你已经学会了在不需要光的情况下穿越田野。
基本概念和术语
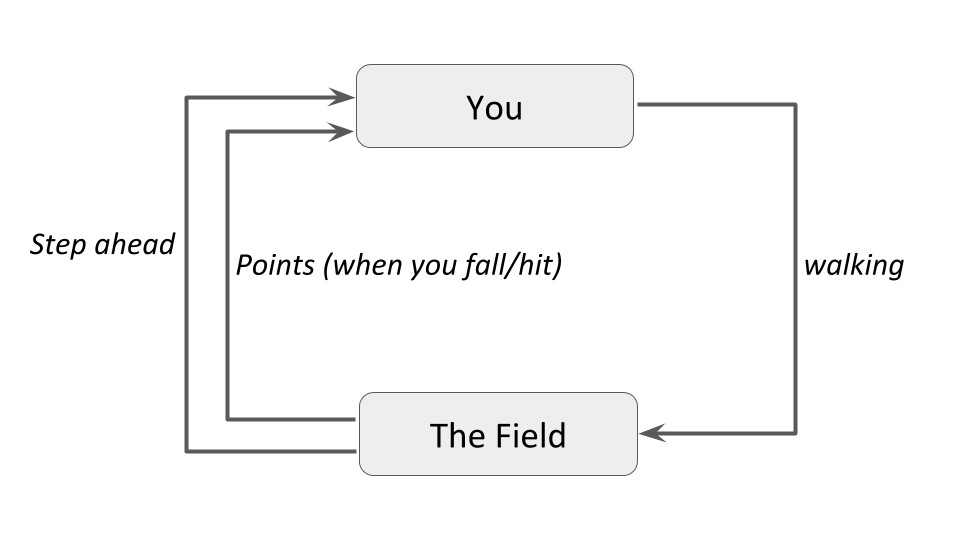
洞察力
在上面的示例中, 你是试图跨过环境(即环境)的代理。步行是代理对环境执行的动作。代理人行走的距离作为奖励。代理试图以使报酬最大化的方式执行动作。简而言之, 这就是强化学习的工作方式。下图将其放入一个简单的图中-
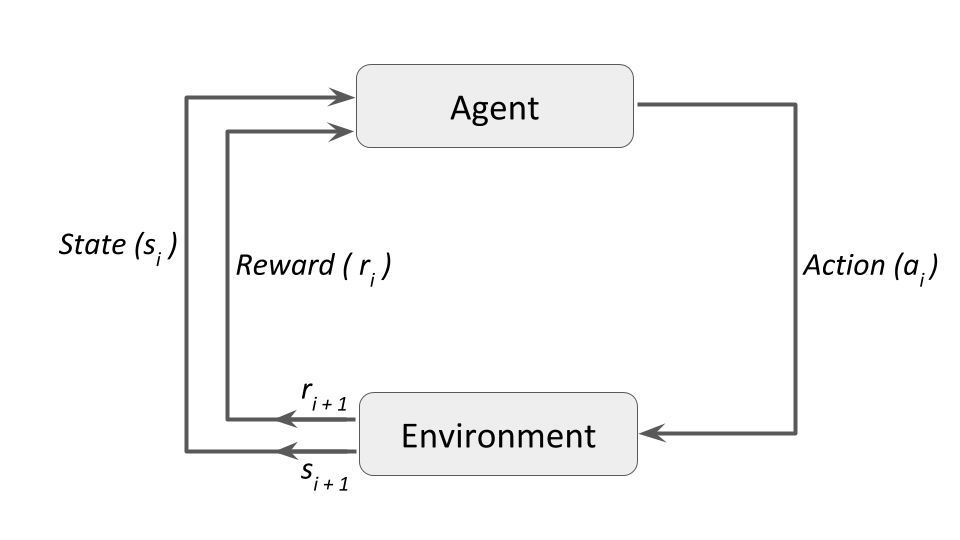
在适当的技术术语上, 并进行概括以适合更多示例, 该图将变为-
术语
与强化学习相关的一些重要术语是(这些术语摘自Steeve Huang的”各种强化学习算法简介”第一部分)-
- 代理人:一个假想的实体, 可以在环境中执行动作以获取一定的回报。
- 行动(a):特工可以采取的所有可能的行动。
- 环境(e):代理必须面对的场景。
- 状态:环境返回的当前状态。
- 奖励(R):从环境发送回的立即回报, 以评估代理的最后一个动作。
- 策略(π):代理用于基于当前状态确定下一步操作的策略。
- 值(V):与短期奖励R.Vπ(s)相对, 带有折扣的预期长期收益被定义为在策略π下当前状态s的预期长期收益。
- Q值或操作值(Q):Q值类似于Value, 不同之处在于它需要一个额外的参数, 即当前操作a。 Qπ(s, a)表示当前状态s的长期返回, 在策略π下采取措施a。
强化学习的工作原理
主要有三种方法来实现强化学习算法。他们是 –
基于价值:在基于价值的强化学习方法中, 你尝试使价值函数V(s)最大化。如先前术语中所定义, Vπ(s)是策略π下当前状态s的预期长期回报。因此, V(s)是代理商期望从该状态s开始在将来获得的奖励价值。
基于策略的:在基于策略的强化学习方法中, 你尝试提出一种策略, 以使在每个状态下执行的操作最佳, 从而在将来获得最大的回报。在此, 不涉及任何价值函数。我们知道, 策略π决定任何状态s的下一个动作a。基于策略的RL方法有两种类型:确定性方法:在任何状态s下, 策略π都会产生相同的动作a。随机的:每个动作都有一定的概率, 由以下等式给出-
基于模型的:在这种类型的强化学习中, 你将为每个环境创建一个虚拟模型, 并且代理将学习在该特定环境中的表现。由于每个环境的模型都不相同, 因此对于这种类型没有单一的解决方案或算法。
一个简单的实现
强化学习带有其自己的经典示例-多臂强盗问题。从没听说过?别担心!就是这样-假设你在赌场里, 并且有一些老虎机。假设你所在的区域连续有10台老虎机, 并且上面写着”免费玩!最大支出为10美元”, 每台老虎机一定会给你0到10美元的奖励。每台老虎机的平均支出都不同, 因此你必须确定哪一台老虎机的平均收益最高, 以便你可以在最短的时间内获得最大的收益。
但是为什么将其称为”多武装强盗”问题?可以将老虎机视为单臂(单杠杆)匪徒(因为它通常会窃取你的钱!)。多台老虎机, 因此是多臂匪。
而且, 如果你仍然想知道, 这就是老虎机的样子-

资料来源:未来
一种非常明显的方法是每次都拉相同的杠杆。碰到大奖的概率非常低, 这样做通常会使你亏本。从形式上讲, 这可以定义为一种纯粹的利用方法。
或者, 你可以拉动每台老虎机的控制杆, 以希望其中至少有一个会中奖。这是另一种幼稚的方法, 会给你次优的回报。正式而言, 此方法是纯探索方法。
eps(ε)-贪心算法
解决强化学习问题的一种非常著名的方法是ϵ(ε)贪婪算法, 这样, 概率为ϵ, 你将随机选择一个动作a(探索), 其余时间选择一个动作a(概率为1-ϵ ), 你将根据你过去的演练(开发)所掌握的知识来选择最佳杠杆。因此, 大多数时候你会贪婪, 但有时你会冒一些风险, 选择一个随机的杠杆来看看会发生什么。
import numpy as np
import random
import matplotlib.pyplot as plt
%matplotlib inline
np.random.seed(5)
首先, 导入实现算法所需的必要库和模块。
n = 10
arms = np.random.rand(n)
eps = 0.1 #probability of exploration action
你将要解决10臂强盗问题, 因此n =10。臂是长度为n的numpy数组, 填充有随机浮点, 可以理解为该臂的动作概率。
def reward(prob):
reward = 0
for i in range(10):
if random.random() < prob:
reward += 1
return reward
奖励功能按此方式工作-对于每个手臂, 你运行10次迭代的循环, 并每次生成随机浮点数。如果此随机数小于该机械臂的概率, 则将奖励加1。在所有迭代之后, 你将获得一个介于0到10之间的值。
为什么只在随机数小于该臂的概率时才添加1?为什么不多呢?答案是, 假设你的手臂概率为0.8。你希望正面回应中有10分之8。这表示肯定的响应应该在数字线上概率值的左侧。
#initialize memory array; has 1 row defaulted to random action index
av = np.array([np.random.randint(0, (n+1)), 0]).reshape(1, 2) #av = action-value
#greedy method to select best arm based on memory array
def bestArm(a):
bestArm = 0 #default to 0
bestMean = 0
for u in a:
avg = np.mean(a[np.where(a[:, 0] == u[0])][:, 1]) #calculate mean reward for each action
if bestMean < avg:
bestMean = avg
bestArm = u[0]
return bestArm
你定义的下一个功能是到目前为止选择最佳手臂的贪婪策略。该函数接受一个存储阵列, 用于存储所有动作及其奖励的历史记录。它是一个2 x k的矩阵, 其中每一行都是对你的arm数组(第一个元素)和所获得的奖励(第二个元素)的索引引用。例如, 如果你的内存阵列中的一行为[2, 8], 则表示采取了行动2(在我们的arm阵列中的第三个元素), 并且你因采取该行动而获得了8的奖励。
这是每个游戏的主要循环。让我们玩500次, 并显示平均奖励与游戏次数对比的matplotlib散点图。
plt.xlabel("Number of times played")
plt.ylabel("Average Reward")
for i in range(500):
if random.random() > eps: #greedy exploitation action
choice = bestArm(av)
thisAV = np.array([[choice, reward(arms[choice])]])
av = np.concatenate((av, thisAV), axis=0)
else: #exploration action
choice = np.where(arms == np.random.choice(arms))[0][0]
thisAV = np.array([[choice, reward(arms[choice])]]) #choice, reward
av = np.concatenate((av, thisAV), axis=0) #add to our action-value memory array
#calculate the mean reward
runningMean = np.mean(av[:, 1])
plt.scatter(i, runningMean)

正如预期的那样, 你的经纪人会学会选择经过多次游戏玩法才能赋予其最大平均回报的手臂。因此, 你已经实现了一种简单的强化学习算法来解决多臂强盗问题。
总结
强化学习由于其广泛用于解决与现实世界场景相关的问题而在当今变得越来越流行。它已在以下领域找到了重要的应用-
- 博弈论和多智能体交互-强化学习已被广泛用于通过软件进行游戏。最近的一个例子是Google的DeepMind, 它能够击败全球排名最高的围棋选手, 后来又击败了评分最高的国际象棋程序科莫多。
- 机器人技术-机器人通常依靠强化学习来在所呈现的环境中表现更好。强化学习的好处是可以为那些可能不得不面对未知或不断变化的环境的机器人提供”一劳永逸”的解决方案。一个著名的例子是Google X的学习机器人项目。
- 车辆导航-车辆在轨道上重跑时会学会更好地导航。该视频中提供了概念证明, 而在视频中的O’Reilly AI大会上则提供了一个现实世界的例子。
- 工业物流-工业任务通常在强化学习的帮助下实现自动化。随着时间的流逝, 促进其工作的软件代理会变得更好。 BonsAI是一家致力于将此类AI引入行业的初创公司。
与我们上面演示的简单算法相比, 还有更多的强化学习算法需要探索, 并且有许多性能更好。请查看参考和链接, 以找到一些快速的地方来开始你的探索, 并将其与本教程的利用相结合, 以增强你对该主题的学习!
如果你想学习更多有关Python的知识, 请参加srcmini的Python时间序列数据机器学习课程。
参考文献
参考文献
- Sutton, Richard S.和Barto, Andrew G., 《强化学习:入门》, 麻省理工学院出版社, 1998年
- 麻省大学阿默斯特分校强化学习资料库
- 维基百科有关强化学习的文章
- 深度强化学习入门指南
链接
如果你仍然有疑问或希望阅读有关强化学习的更多信息, 那么这些链接可以是一个很好的起点-
- 强化学习中的术语表
- 强化学习参考书目
- David J. Finton的强化学习页面
- 斯坦福大学吴安健强化学习讲座
评论前必须登录!
注册