 srcmini
srcmini本文概述
描述H2O
人们对机器学习算法议论纷纷,对它的专家也提出了要求。我们都知道, 技能要求存在很大差距。 H2O的动机是提供一个平台, 使非专业人员可以轻松地进行机器学习实验。
H2O体系结构可以分为不同的层, 其中顶层是不同的API, 底层是H2O JVM。
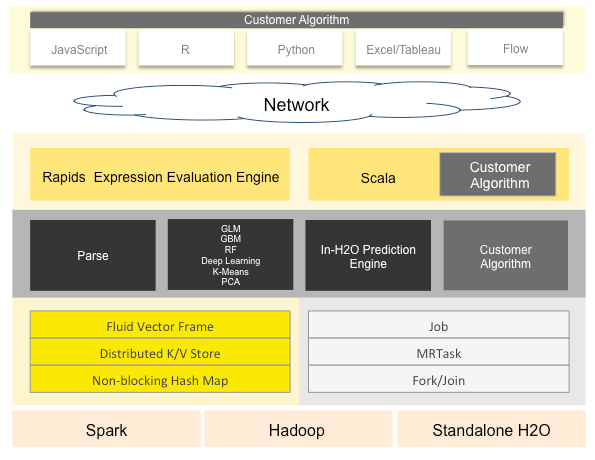
资源
H2O的核心代码是用Java编写的, 它使整个框架能够实现多线程。尽管它是用Java编写的, 但它提供了R, Python和体系结构中所示的其他少数几个接口, 从而使它可以有效地使用。
在症结所在, 我们可以说H2O是内存中的开源, 分布式, 快速且可扩展的机器学习和预测分析, 可轻松构建机器学习模型。
安装过程
[R
如果要在R中使用H2O功能, 只需使用命令install.packages(” h2o”)安装软件包H2O。
library(h2o)
##
## ----------------------------------------------------------------------
##
## Your next step is to start H2O:
## > h2o.init()
##
## For H2O package documentation, ask for help:
## > ??h2o
##
## After starting H2O, you can use the Web UI at http://localhost:54321
## For more information visit http://docs.h2o.ai
##
## ----------------------------------------------------------------------
##
## Attaching package: 'h2o'
## The following objects are masked from 'package:stats':
##
## cor, sd, var
## The following objects are masked from 'package:base':
##
## %*%, %in%, &&, ||, apply, as.factor, as.numeric, colnames, ## colnames<-, ifelse, is.character, is.factor, is.numeric, log, ## log10, log1p, log2, round, signif, trunc
h2o.init()
## Connection successful!
##
## R is connected to the H2O cluster:
## H2O cluster uptime: 32 minutes 57 seconds
## H2O cluster timezone: Asia/Kolkata
## H2O data parsing timezone: UTC
## H2O cluster version: 3.20.0.2
## H2O cluster version age: 3 months and 22 days !!!
## H2O cluster name: H2O_started_from_R_NSingh1_wou076
## H2O cluster total nodes: 1
## H2O cluster total memory: 1.55 GB
## H2O cluster total cores: 4
## H2O cluster allowed cores: 4
## H2O cluster healthy: TRUE
## H2O Connection ip: localhost
## H2O Connection port: 54321
## H2O Connection proxy: NA
## H2O Internal Security: FALSE
## H2O API Extensions: Algos, AutoML, Core V3, Core V4
## R Version: R version 3.5.1 (2018-07-02)
如果你没有64位的Jdk, 初始化H2O可能会在你的系统中引发错误。如果出现此类问题, 请安装最新的64位Jdk, 之后它将正常工作。
python
如果你使用的是python, 则也会应用相同的方法, 从命令行pip install -U h2o和h2o将为你的python环境安装。初始化h2o的过程将相同。
h2o.init()命令非常聪明, 可以完成很多工作。首先, 它将在启动新实例之前查找任何活动的h2o实例, 然后在不存在实例时启动一个新实例。
它确实具有一些参数, 这些参数有助于为经常使用的h2o实例提供资源:
- nthreads:默认情况下, nthreads的值为-1, 这意味着实例可以使用CPU的所有内核, 我们可以通过将值传递给参数来设置使用的内核数。
- max_mem_size:通过将值传递给此参数, 可以限制分配给实例的最大内存。它的od字符串类型可以为2 GB的内存传递参数” 2g”或” 2G”, 与要分配的MB相同。
创建实例后, 你可以通过在浏览器中键入http:// localhost:54321来访问流。 Flow是属于h2o的Web界面的名称, 它不需要任何额外的安装, 而是使用CoffeeScript(类似于JavaScript的语言)编写的。你可以将其用于执行以下操作:
- 直接上传数据
- 查看客户端上传的数据
- 直接创建模型
- 查看你或你的客户创建的模型
- 查看预测
- 直接运行预测
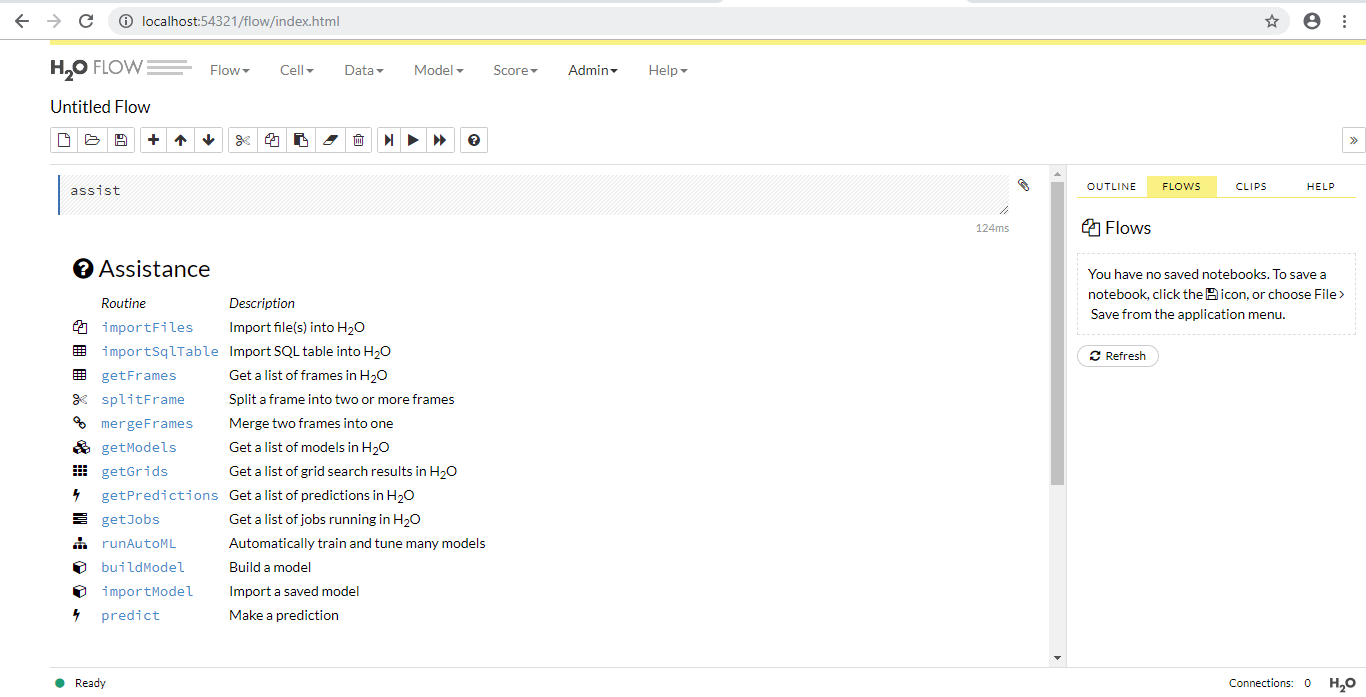
该界面非常有用, 并且可以方便非专家使用, 我建议你尝试一下并进行一些自己的实验。
Auto语言
现在谈论H2O的AutoML部分, AutoML帮助在用户指定的时间限制内Auto训练和调整许多模型。
当前版本的AutoML函数可以训练并交叉验证随机森林, 极端随机森林, 梯度提升机(GBM)的随机网格, 深度神经网络的随机网格, 然后使用所有模型。
当我们说AutoML时, 它应该迎合数据准备, 模型生成和集成的各个方面, 并且还应提供尽可能少的参数, 以便用户能够以更少的混乱来执行任务。 H2o AutoML确实很容易执行此任务, 并且用户传递的参数最少。
在R和Python API中, 它使用与数据相关的相同参数x, y, training_frame, 验证帧, 其中y和training_frame是必需参数, 其余参数是可选的。你还可以在此处配置max_runtime_sec和max_models的值, 其中max_runtime_sec参数是必需的, 如果不传递任何参数, 则max_model是可选的, 默认情况下其值为NULL。
x参数是training_frame中预测变量的向量, 如果你不想使用所传递帧中的所有预测变量, 则可以将其传递给x进行设置。
现在, 让我们谈谈一些可选参数和其他参数, 即使你不知道这些参数, 也要尝试对其进行调整, 这将使你获得一些高级主题的知识:
- validation_frame:此参数用于提早停止automl中的各个模型。它是你传递以用于模型验证的数据框, 或者如果你未传递则可以是训练数据的一部分。
- Leaderboard_frame:如果通过, 则将根据值对模型评分, 而不使用交叉验证指标。同样, 如果你未通过这些值, 则它们也是训练数据的一部分。
- nfolds:默认情况下, K折交叉验证5可用于降低模型性能。
- fold_columns:指定交叉验证的索引。
- weights_column:如果要为特定的列提供权重, 则可以使用此参数, 将权重分配为0表示你要排除该列。
- ignore_columns:仅在python中, 它与x相反。
- starting_metric:指定一个用于早期停止网格搜索的度量, 并且模型的默认值是对数损失(logloss)(分类)和偏差(回归)。
- sort_metric:用于对排行榜模型进行排序的参数。对于二进制分类, 默认为AUC;对于多项分类, 默认为mean_per_class_error;对于回归, 默认为deviance。
validation_frame和Leaderboard_frame取决于交叉验证参数, 即nfolds。
在两种情况下, 可能会产生以下情况:
当我们在automl中使用交叉验证时:*仅传递训练帧-然后数据将分成80-20个训练和验证帧。 *通过了培训和排行榜框架-培训和验证框架中的80-20数据分割没有变化。 *通过训练和验证框架时-不拆分。 *当所有三个帧都通过时-不分割。
当我们不使用交叉验证时, 交叉验证会大大影响排行榜框架(nfolds = 0):*仅通过训练框架-数据分为80/10/10训练, 验证和排行榜。 *通过了培训和排行榜框架-数据分为80-20个培训和验证框架。 *通过训练和验证框架时-验证框架数据分为50-50个验证和页首横幅。 *当所有三个帧都通过时-不分割。
在R和Python中实现
R
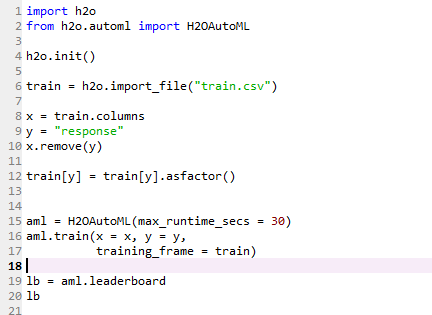
H2O将数据导入为Frame, 这与我们在R和Python中用于不同操作的数据帧不同。
train <- h2o.importFile("train.csv")
##
|
| | 0%
|
|=================================================================| 100%
test <- h2o.importFile("test.csv")
##
|
| | 0%
|
|=================================================================| 100%
设置预测变量和响应。
y <- "response"
x <- setdiff(names(train), y)
通过传递必需参数来创建automl对象。我们仅传递训练帧, 并且nfolds参数具有其默认值。你可以根据需要增加模型的运行时间。
train[, y] <- as.factor(train[, y])
aml <- h2o.automl(x = x, y = y, training_frame = train, max_runtime_secs = 30)
##
|
| | 0%
|
|= | 1%
|
|= | 2%
|
|== | 3%
|
|=== | 4%
|
|=== | 5%
|
|==== | 6%
|
|===== | 8%
|
|====== | 9%
|
|====== | 10%
|
|======== | 13%
|
|========== | 15%
|
|========== | 16%
|
|=========== | 16%
|
|=========== | 17%
|
|=========== | 18%
|
|============ | 18%
|
|============================================================== | 95%
|
|=================================================================| 100%
查看不同型号的页首横幅。
lb <- aml@leaderboard
lb
## model_id auc
## 1 StackedEnsemble_AllModels_0_AutoML_20181008_110411 0.7823564
## 2 StackedEnsemble_BestOfFamily_0_AutoML_20181008_110411 0.7789898
## 3 GBM_grid_0_AutoML_20181008_110411_model_0 0.7738653
## 4 GBM_grid_0_AutoML_20181008_110411_model_1 0.7720842
## 5 GBM_grid_0_AutoML_20181008_110411_model_2 0.7713380
## 6 DRF_0_AutoML_20181008_110411 0.7456390
## logloss mean_per_class_error rmse mse
## 1 0.5596939 0.3197364 0.4359927 0.1900896
## 2 0.5628477 0.3112125 0.4374262 0.1913417
## 3 0.5662489 0.3164375 0.4393990 0.1930715
## 4 0.5679111 0.3192612 0.4402417 0.1938127
## 5 0.5679935 0.3297330 0.4405557 0.1940894
## 6 0.5985811 0.3611326 0.4520878 0.2043834
##
## [8 rows x 6 columns]
python
如果你想学习更多有关Python的知识, 请参加srcmini的Dask并行计算课程。
评论前必须登录!
注册